Exploring the Landscape of Large Language Models
Evolution and Market Trends
In recent years, the world has witnessed an unprecedented surge in interest and investment in the field of Artificial Intelligence (AI). This phenomenon has been driven by a confluence of factors, including advances in machine learning, the availability of vast datasets, and the ever-expanding computational capabilities of modern technology. At the forefront of this AI revolution stands Large Language Models (LLMs), a category of deep learning models designed to understand and generate human language. This transformation has not only redefined the technological paradigm but has also reshaped the economic and investment landscape. In this report, we explore the evolution of LLM technology, its applications, the competitive landscape, and the investment prospects it presents.
Definition of Large Language Models
Large language models are AI systems engineered to handle extensive natural language data, utilizing this information to generate responses to user queries. They are trained on massive datasets through advanced machine learning algorithms, enabling them to discern the patterns and structures of human language and produce natural responses across diverse written inputs. These models are gaining significance in applications like natural language processing, machine translation, code generation, and beyond.
A large language model (LLM) is defined by its substantial size, made possible by AI accelerators capable of processing extensive text data, often gathered from the internet. LLMs are artificial neural networks containing billions to trillions of parameters, and they undergo (pre-)training using self-supervised and semi-supervised learning techniques. The Transformer architecture contributed to expediting their training. An alternative architecture, the mixture of experts (MoE), was proposed by Google in 2017.
LLMs predict the next token or word in a sequence when provided with input text. LLMs are believed to accumulate knowledge about the syntax, semantics, and "ontology" found in human language corpora, but they may also inherit inaccuracies and biases present in the data. Prominent examples of LLMs include OpenAI's GPT models (such as GPT-3.5 and GPT-4, used in ChatGPT), Google's PaLM (utilized in Bard), Meta's LLaMa, and others like BLOOM, Ernie 3.0 Titan, and Anthropic's Claude 2.
Evolution of LLMs Technology
Table 1. The History of LLMs
| Timeline | Evolution |
|---|---|
| 1950s–1990s | In the initial decades, attempts were made to establish rigid language rules and follow logical procedures to achieve tasks like language translation. While this approach yielded results on occasion, it was effective only for specific, well-defined tasks that the system had prior knowledge of. |
| 1990s | Language models began to transition into statistical models, with the analysis of language patterns. However, the scope of larger-scale projects was constrained by limited computing power. |
| 2000s | Advancements in machine learning led to more intricate language models. The widespread use of the internet contributed to a substantial increase in available training data. |
| 2012 | Breakthroughs in deep learning architectures and the availability of larger datasets culminated in the development of GPT (Generative Pre-trained Transformer). |
| 2018 | Google introduced BERT (Bidirectional Encoder Representations from Transformers), a significant leap in architectural innovation that paved the way for future large language models. |
| 2020 | OpenAI unveiled GPT-3, the largest model to date with 175 billion parameters, setting a new standard for performance in language-related tasks. |
| 2022 | The launch of ChatGPT transformed models like GPT-3 into widely accessible services through a web interface, sparking a substantial increase in public awareness of Large Language Models (LLMs) and generative AI. |
| 2023 | Open source LLMs, including releases like Dolly 2.0, LLaMA, Alpaca, and Vicuna, began to deliver increasingly impressive results. Concurrently, the release of GPT-4 set new benchmarks in both parameter size and performance. |
Stages in the Evolution of LLMs:
- N-gram-based Models, 1980: In the early days, statistical language models relied on n-grams to assess the likelihood of word sequences. These models were straightforward but served as a foundation for language modelling.
- Neural Network-based Models, late 2000s and early 2010s: The emergence of deep learning brought neural network-based language models into the spotlight. These models utilize deep neural networks to learn language patterns. Each word is represented as a vector, and the network processes them, enhancing efficiency compared to n-grams.
- Recurrent Neural Network (RNN) Models, early 2010s: RNN language models, leveraging specialized networks for sequences, consider contextual information, improving performance. However, they face challenges like vanishing gradients when dealing with long sequences.
- Long Short-Term Memory (LSTM) Models, early 2010s: LSTMs were introduced to tackle gradient-related issues in RNNs. They excel at capturing dependencies in lengthy sequences, enhancing overall performance.
- Gated Recurrent Unit (GRU) Models, early 2010s: GRUs, a simpler variant of LSTMs, maintain sequence processing capabilities with fewer parameters. This results in quicker training and competitive performance in certain applications.
- Large-scale Pretrained Models, ~2018: The latest trend involves large-scale pretrained language models. They leverage self-supervised learning on massive text datasets to create pretrained models like BERT, GPT, and XLNet. After fine-tuning on specific data, these models have demonstrated exceptional performance across various natural language processing tasks.
Deep into LLM Technology & Comparison
Booming in Recent Years
Large language models (LLMs) typically pertain to Transformer-based language models with hundreds of billions or more parameters. These models undergo extensive training on vast text datasets. Prominent examples include GPT-3, PaLM, Galactica, and LLaMA. LLMs demonstrate robust capabilities in comprehending natural language and addressing intricate tasks, particularly in text generation. To gain a brief insight into LLMs' operation, this section provides fundamental context on LLMs, encompassing scaling principles, emerging capabilities, and essential techniques.
Figure 1. The Evolution of Large Language Models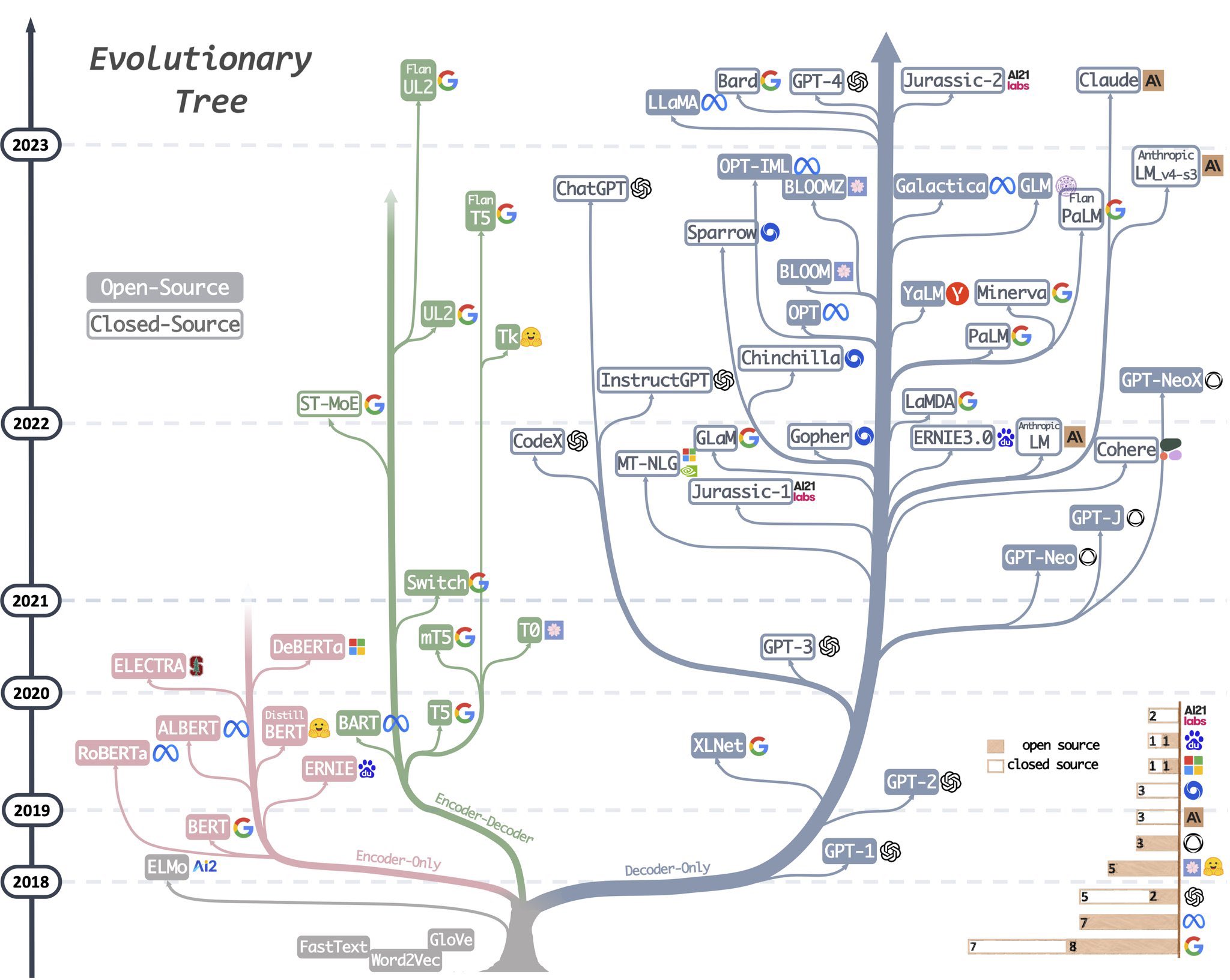 Source: “Getting Started and Follow GPT Path Analysis”
Source: “Getting Started and Follow GPT Path Analysis”
Decoder-only models exclusively comprise the decoding component, lacking an encoder. They offer distinct advantages over Encoder-Decoder models:
- Simplicity and Speed: With no encoder component, Decoder-only models have fewer parameters and demand less computation. This simplicity accelerates both training and inference, enhancing efficiency. With no encoder, they have fewer parameters, making training and inference faster and more efficient.
- Tailored for Pure Generation Tasks: Decoder-only models focus solely on generating output sequences, making them well-suited for tasks like text generation, story creation, and dialogue generation that involve pure content generation.
- Mitigating Training Complexities: Training only a decoder sidesteps challenges often encountered in Encoder-Decoder training, including issues related to different weight initializations and the avoidance of information bottlenecks.
- Decoder Self-Supervision: In Decoder-only model training, the output from the previous step becomes the input for the next one. This self-supervision mechanism promotes the generation of coherent and structured output sequences.
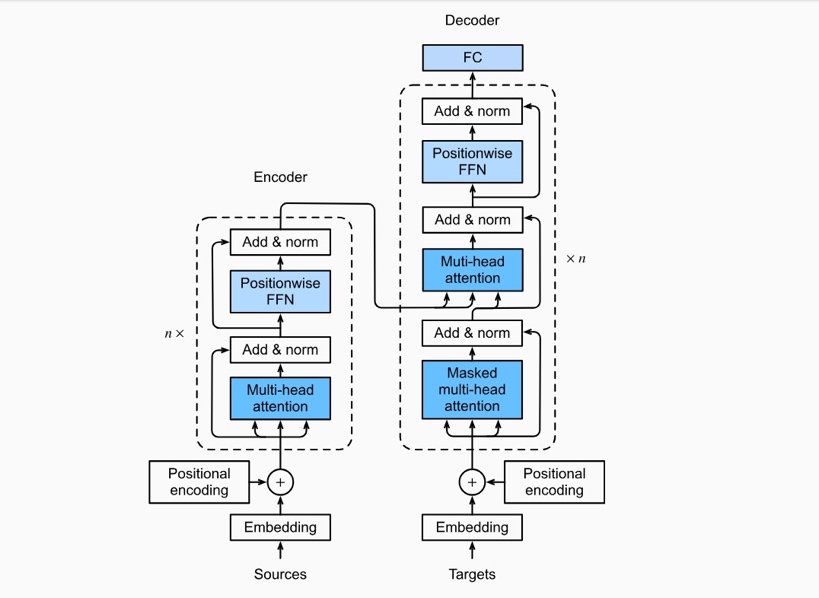
Table 2.Recent Developments of LLMs
| Encoder-Only Models (Red) | Encoder-Decoder Models (Green) |
Decoder-Only Models (Blue) | |
|---|---|---|---|
| Workflow | 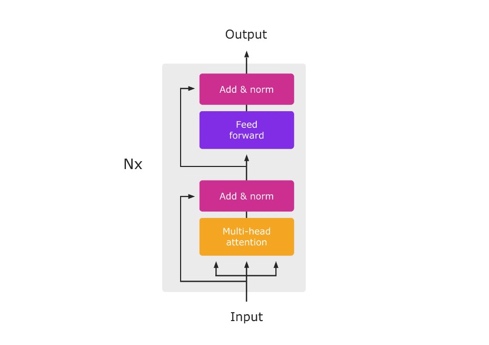 |
 |
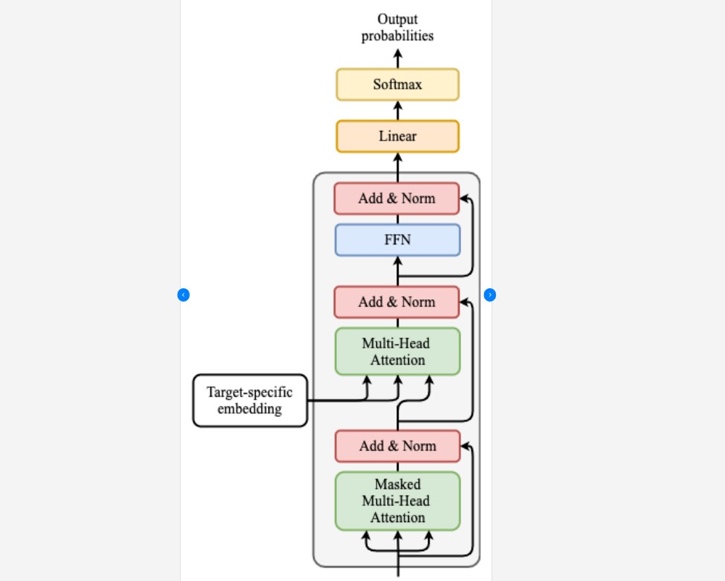 |
| These models, initially led by BERT, have seen reduced development after 2020. While they have simple structures and are faster for certain tasks, they excel less in complex sequence-to-sequence tasks. | Companies like Google have been favouring this approach. These models exhibit strong sequence learning and generation capabilities, making them ideal for tasks like translation and summarization. However, they are computationally intensive. | This category, including GPT-1 and models from various companies, focuses solely on the decoding part, omitting the encoder. They offer simplicity, faster training, and are suitable for pure generation tasks. They also bypass some training challenges but are not as powerful in complex sequence tasks as Encoder-Decoder models. | |
| Training Approach | Masked Language Model | Autoregressive Language Model | |
| Model Type | Discriminative | Generative | |
| Pre-training Task | Predicting masked words | Predicting next word | |
| Representative Models | ELMo, BERT, RoBERTa, DistilBERT, BioBERT, XLM, Xlnet, ALBERT, ELECTRA, T5, XLM-E, ST-MoE, AlexaTM | GPT-3, OPT,PaLM, BLOOM, GLM, MT-NLG, GLaM,Gopher, chinchilla, LaMDA, GPT-J, LLaMA, GPT-4, BloombergGPT |
Source: “A Comprehensive Comparison Of Open Source LLMs”
- Key Change - The Transformer
The Transformer is a deep learning model introduced by Google Brain in 2017, widely used in natural language processing (NLP). Its key features include self-attention for capturing dependencies, encoder-decoder architecture for sequence tasks, multi-head attention, positional encoding, and layer normalization. Transformers revolutionized NLP by handling long-range dependencies, and they are the foundation for many large pretrained language models like BERT and GPT, driving advances in the field.
Figure 2. A Timeline of Existing Large Language Models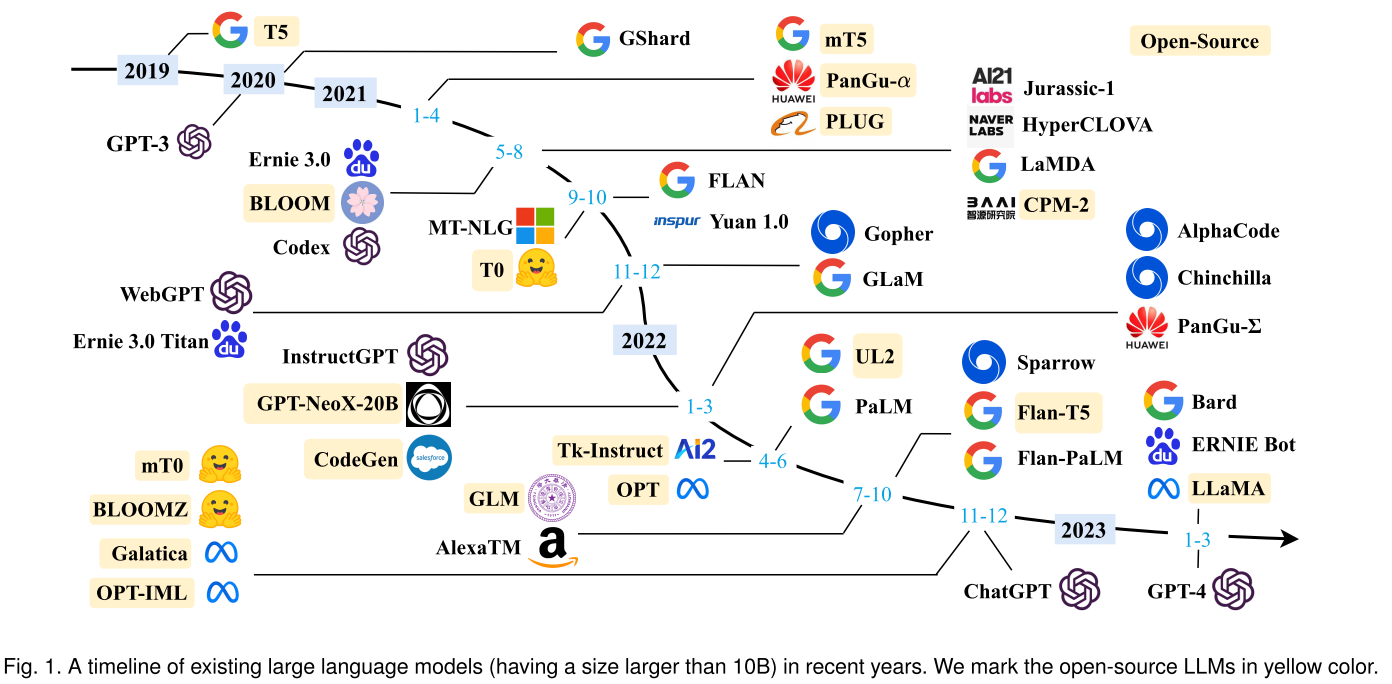 Source: Medium
Source: Medium
LLM Workflow
At a broad level, the process of training a Large Language Model (LLM) encompasses three primary phases: data collection, training, and evaluation.
- Step1: Data Collection: Initially, data is accumulated from a diverse array of sources, which may encompass, but are not limited to, Wikipedia, news articles, books, and websites. This multifaceted dataset forms the fundamental basis for the model's training.
- Step 2: Training: The collected data undergoes a rigorous pre-processing and cleansing procedure before integration into the training pipeline. This training phase is both computationally demanding and time-intensive, necessitating substantial computational resources.
- Step3: Evaluation: In the final stage, the model's performance is scrutinized across various tasks, including question answering, summarization, translation, and more. This evaluation serves to measure the model's efficacy and suitability for diverse language-related applications.
The culmination of this training pipeline results in an LLM model, characterized by its acquired parameters or weights. These parameters are typically serialized and stored in a file, enabling their utilization in a wide array of applications that require language processing capabilities, spanning text generation, question answering, and natural language processing, among others.
Figure 3. The Understanding of Large Language Models Source: “Introduction to LLMs”
Source: “Introduction to LLMs”
Cost of LLMs
Advancements in both software and hardware have significantly reduced costs in recent years.
- In 2023, training a 12-billion-parameter Large Language Model (LLM) requires approximately 72,300 A100-GPU-hours;
- To put this in perspective, back in 2020, training a 1.5-billion-parameter LLM, which was considerably smaller than the state-of-the-art at the time, cost anywhere from $80,000 to $1.6 million.
The investment in larger models has been substantial since 2020.
- For instance, training the GPT-2, a 1.5-billion-parameter model, in 2019 cost $50,000;
- In contrast, training PaLM, a massive 540-billion-parameter model in 2022, came with a staggering price tag of $8 million.
It's worth noting that for Transformer-based LLMs, the cost of training far exceeds the cost of inference.
- Training consumes about 6 FLOPs (Floating-Point Operations) per parameter per token;
- Inference typically ranges from 1 to 2 FLOPs per parameter per token. This distinction highlights the substantial computational resources required for training these models.
Table 3.Yearly Costs Based On Usage And OpenAI Model
| Model | GPT-3.5 4K Context | GPT-3.5 16K Context | GPT-4 8K Context | GPT-4 32K Context | Cloud-Hosted 7B params | Cloud-Hosted 40B params |
|---|---|---|---|---|---|---|
| Yearly cost – 1K requests per day | $949 | $1,898 | $28,470 | $56,940 | $26,280 | $175,200 |
| Yearly cost – 1M requests per day | $949,000 | $1,898,000 | $28,470,000 | $56,940,000 | $29,930 | $178,850 |
Source: “The Economics of Large Language Models”
- GPT-3.5/4 API Costs: ChatGPT API is priced at $0.002 for 1,000 tokens. For lower usage, the cost is reasonable, but processing a million documents a day can cost around $1 million a year. More powerful models like GPT-4 have varying costs based on usage, ranging from $1,000 to $56 million annually.
- Open-Source Model Hosting Costs: Hosting LLMs involves GPU RAM and hourly charges. For a 7 billion parameter model at 16-bit precision, it would cost around $2-3 per hour. Larger open-source models require more GPU memory and can cost around $20 per hour.
- On-Premises Hosting Costs: Running LLMs on private servers requires high-quality GPUs, which can be expensive. Scaling up on-premises involves purchasing additional infrastructure, setting it up, and handling maintenance. It's important to consider other cloud-related infrastructure, such as load balancers, for maintaining network traffic and ensuring low latency.
LLMs Comparison
Key Factors
- Capacity: the number of parameters;
- Pre-training Data Scale: the scale of the pre-training data in terms of tokens or storage size;
- Hardware Resource Costs: the computational resources required;
- Release Time: the official release date of the corresponding paper;
- Accessibility: distinguishing between publicly available and closed-source models;
- Adaptation: specifying whether the model has undergone subsequent fine-tuning, denoted as IT (instruction tuning) or RLHF (reinforcement learning with human feedback);
- Evaluation: indicating whether the model has been evaluated for specific abilities, such as ICL (in-context learning) or CoT (chain-of-thought).
Table 4: Statistics of Large Language Models (LLMs) with a Size Larger Than 10 Billion Parameters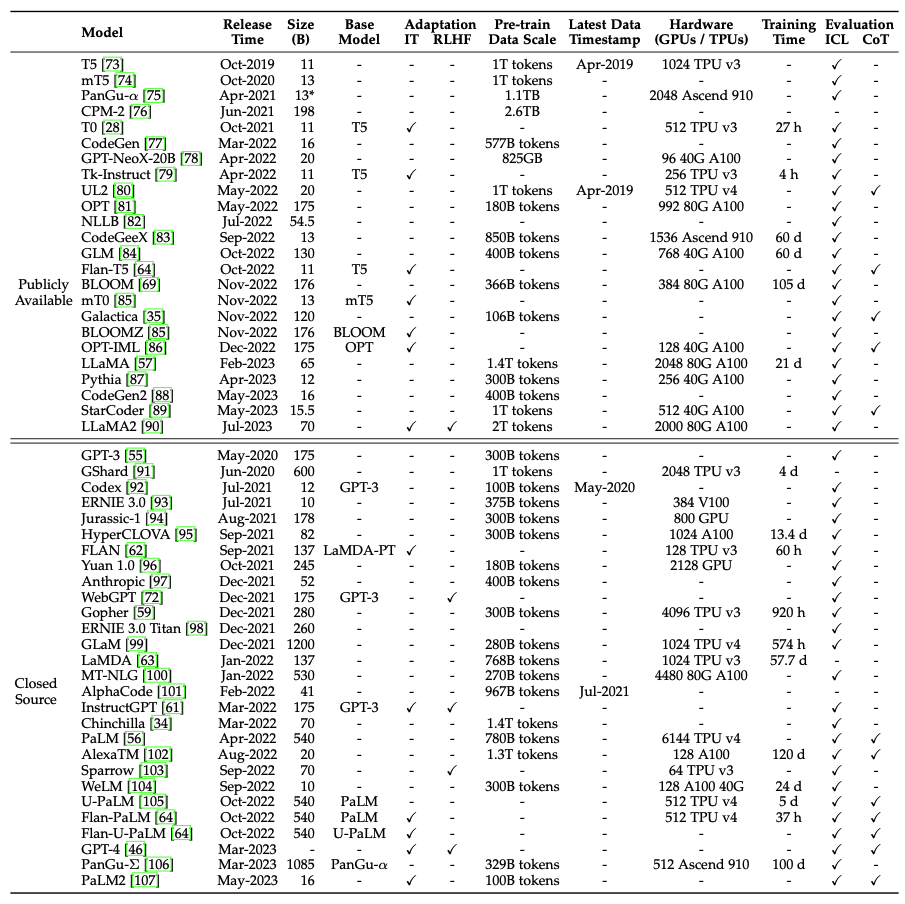 Source: “A Survey of Large Language Models”
Source: “A Survey of Large Language Models”
Parameter Numbers Comparison
Take NL2Code task as an example for LLMs parameter numbers comparison, a comprehensive survey of 27 representative LLMs was conducted for the NL2Code task, and the following table summarizes the detailed information of each model. Model size evolution is as follows:
Figure 4. Numbers of LLMs Parameter Comparison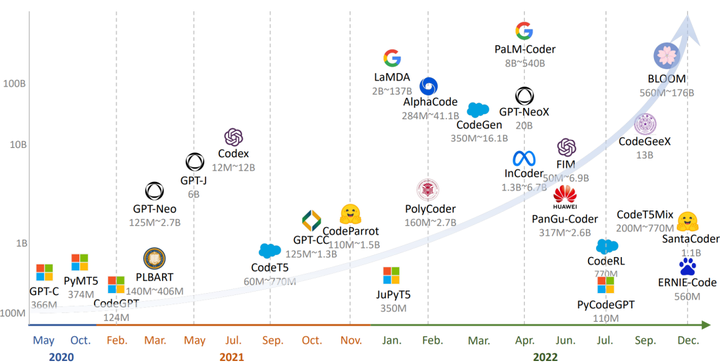 Source: “The Emergence of the Transformer - The Architectural Breakthrough, History, and the Future of The Model Behind ChatGPT”
Source: “The Emergence of the Transformer - The Architectural Breakthrough, History, and the Future of The Model Behind ChatGPT”
According to the figure below, larger models usually produce better results. In addition, the current model, regardless of its size, can still achieve performance improvements by further increasing the model parameters.
Figure 5. LLMs Performance Comparision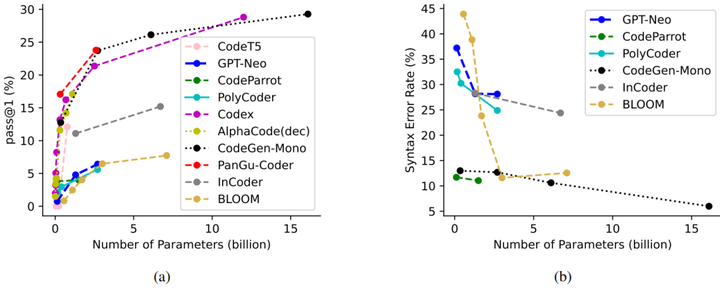 Source: “The Emergence of the Transformer - The Architectural Breakthrough, History, and the Future of The Model Behind ChatGPT”
Source: “The Emergence of the Transformer - The Architectural Breakthrough, History, and the Future of The Model Behind ChatGPT”
LLM Business Strategy
Value Chain Positioning
LLM technology is developed, deployed, and utilized in real-world applications: It starts with the cloud computing infrastructure, moves through the core LLM models, extends to the platforms for sharing and utilizing models, and finally reaches the end-users who benefit from LLM-powered applications.
Table 5. Value Chain Analysis
| Categories | Companies and practice |
|---|---|
| Upstream | - Cloud Computing Platforms: Azure, Google Cloud, AWS, Ali Cloud These are the foundational cloud computing platforms that provide the infrastructure for hosting and running LLM models. |
| Large Language Models | - OpenAI GPT, DeepMind Gopher, Google GlaM, EML, BERT LLMs represent the core language models and technologies used in various applications across the industry chain. |
| Downstream (Parallel Categories) | - Model Hosting and Trading Platforms: Hugging Face, Replicat, LanguageX These platforms offer services for hosting, sharing, and trading LLM models, making them accessible to developers and businesses. - Intermediate Layer This category may include additional services, APIs, or middleware that facilitate the integration of LLMs into various applications. |
| End-users | - Consumer and Business Applications These are the final applications and solutions that leverage LLM technology for both consumer-facing (C-end) and business-facing (B-end) purposes. |
LLM Business Model
Table 6. LLM Business Model
| Approaches | Detail |
|---|---|
| Licensing and Subscription Model | - Many LLM developers and organizations offer licensing or subscription-based access to their models. - This model allows other companies and developers to use LLMs for various purposes, such as natural language understanding, content generation, or customer support. |
| API Services | - Some LLM providers offer Application Programming Interface (API) services, allowing developers to integrate LLM capabilities directly into their applications and services. These services are typically offered on a pay-as-you-go or subscription basis. |
| Customized Solutions | - LLM developers may offer customized solutions tailored to the specific needs of businesses or industries. This can include developing LLMs with specialized training data and fine-tuned parameters for tasks like medical diagnosis, legal document analysis, or financial forecasting. |
| Consulting and Integration Services | - Companies specializing in LLM technology may provide consulting and integration services to help businesses implement LLM solutions into their existing workflows. This can involve training and fine-tuning LLMs for specific use cases. |
| Content Generation and Monetization | - Some organizations leverage LLMs to generate content, such as articles, reports, or creative works, which can be monetized through advertising, subscriptions, or other revenue models. |
| Data Annotation and Enrichment | - LLM technology can be used to annotate and enrich datasets, improving the quality and relevance of data for various industries like e-commerce, recommendation systems, and sentiment analysis. |
| Research and Development Collaborations | - Academic institutions and research organizations may collaborate with LLM developers on joint research projects, contributing to advancements in language modelling and AI. |
| Regulatory and Compliance Solutions | - LLMs can be applied to develop solutions for regulatory compliance, risk assessment, and fraud detection in industries like finance and healthcare. |
| Content Moderation and Safety | - LLMs are utilized for content moderation to identify and mitigate harmful or inappropriate content on online platforms, which can be offered as a service. |
| Government and defence Contracts | - Governments and defence organizations may contract LLM developers to create models for various purposes, including natural language understanding, translation, and information extraction. |
Market Landscape
Market Size
The generative AI market is poised for significant growth, with an expected increase from its 2023 valuation of USD 11.3 billion to a substantial USD 76.8 billion by 2030. This growth will be achieved at an impressive compound annual growth rate (CAGR) of 31.5% throughout the forecast period.
The rapid expansion of the LLM market has been a pivotal growth driver within the broader Generative Al market. In recent years, LLMs have been increasing an average of 10x per year in size and sophistication, ushering in new opportunities for Large Language Model market.
Figure 6. Generative AI Market Global Forecast to 2030 (USD BN)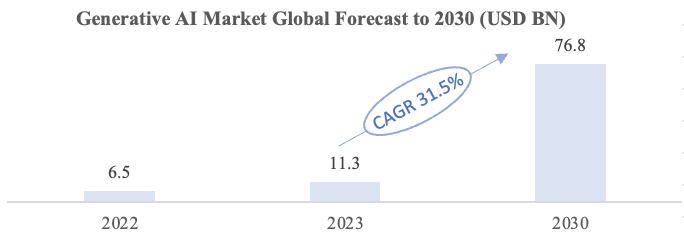 Source: “Generative AI Market”
Source: “Generative AI Market”
Market Map
Large language models, as the infrastructure in the field of artificial intelligence, play an essential role in Generative AI. LLMs have revolutionized natural language processing and understanding by leveraging machine learning advances. Several organizations are actively involved in LLM research and development. Notable players include OpenAI, Google, Meta (formerly Facebook), Hugging Face, Cohere, and Stability AI. Prominent LLM models that have gained attention include GPT-4, Google's PaLM 2, Meta’s LLaMa (Language Learning Model), and Anthropic’s Claude.
Generative AI has diverse vertical use cases, including text generation, music generation, figure generation, and multimodal generation. LLMs facilitate comprehension and reasoning, reshaping the way of human-computer interaction. In terms of applications, we can see that generative AI is opening a new chapter across industries by providing high-quality prompt-based services.
Figure 7. Large Language Models Market Map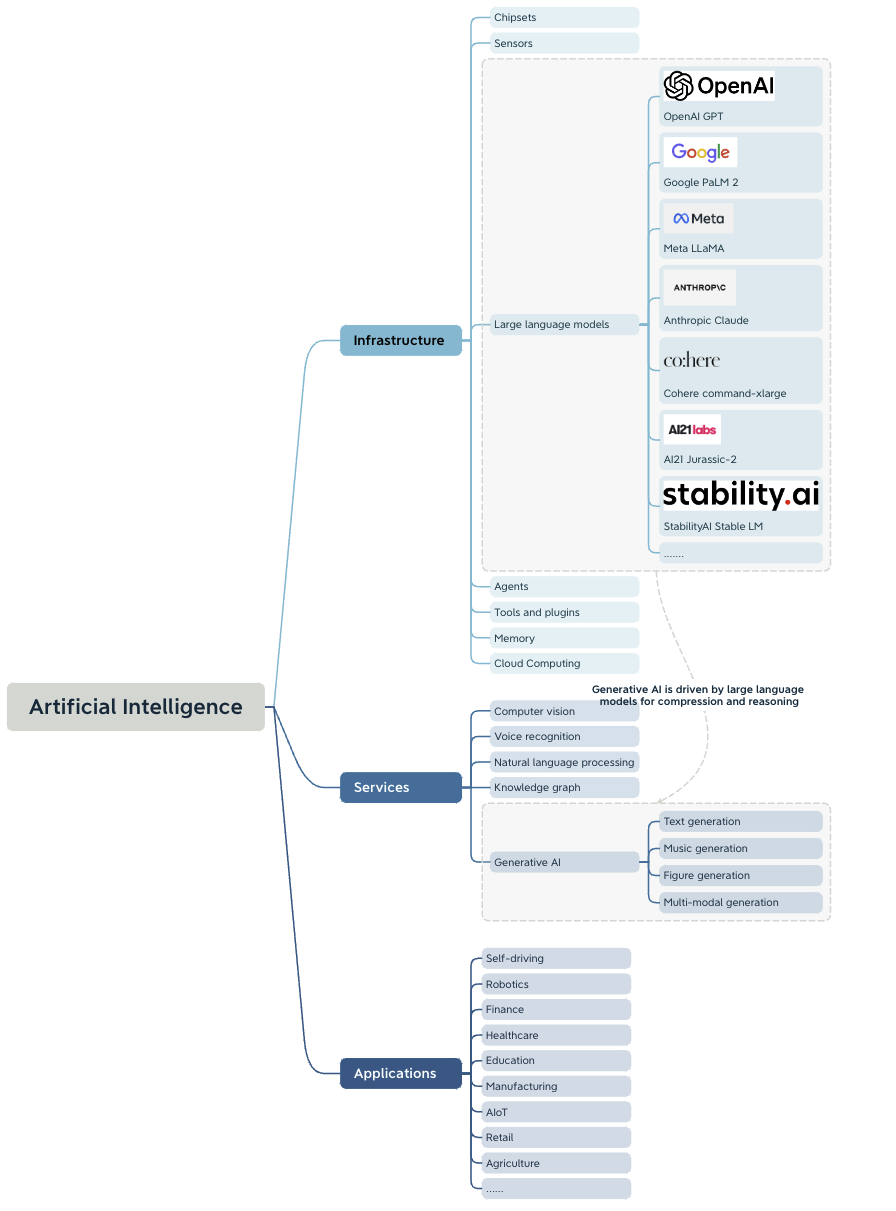
Competitive Landscape Overview
OpenAI has played a significant role in this field in recent years through its models and research endeavours. Nevertheless, the market features a diverse array of other players.
Table 7. Representative Companies in Different Categories
| Categories | Companies and practice |
|---|---|
| Large Technology Companies | - OpenAI is one of the leaders in the LLM field and has developed the GPT family of models, including GPT-3 and GPT-4 - Google has contributed FLAN-T5 and BERT models - Meta has introduced OPT, OPT-IML, and LLaMA models |
| Open Source Communities | - Hugging Face offers pre-trained LLM models and NLP tools - EleutherAI is known for contributing models like GPT-Neo |
| Startups | - Stability AI offers the StableLM |
| Research Organizations & Universities | - Carnegie Mellon University researchers involved in the Tartan - Stanford has developed Alpaca |
Table 8. Latest LLMs Market Players
| Name | Release Date | Developer | Number of Parameters | Corpus Size | Training Cost (petaFLOP-day) | License | Notes |
|---|---|---|---|---|---|---|---|
| BERT | 2018 | 340 M | 3.3 billion words | 9 | Apache 2.0 | An early influential model, encoder-only, not built for prompting or generation. | |
| XLNet | 2019 | ~340 M | 33 billion words | An alternative to BERT, encoder-only. | |||
| GPT-2 | 2019 | OpenAI | 1.5 B | 40GB (~10 billion tokens) | MIT | General-purpose model based on Transformer architecture. | |
| GPT-3 | 2020 | OpenAI | 175 B | 300 billion tokens | 3640 | Proprietary | Fine-tuned variant of GPT-3; GPT-3.5 made available in 2022. |
| GPT-Neo | 2021.3 | EleutherAI | 2.7 B | 825 GiB | MIT | First of free GPT-3 alternatives by EleutherAI. | |
| GPT-J | 2021.6 | EleutherAI | 6 B | 825 GiB | 200 | Apache 2.0 | GPT-3-style language model. |
| Megatron-Turing NLG | 2021.10 | Microsoft and Nvidia | 530 B | 338.6 billion tokens | Restricted web access | Standard architecture, trained on supercomputing cluster. | |
| Ernie 3.0 Titan | 2021.12 | Baidu | 260 B | 4 Tb | Proprietary | Chinese-language LLM. Ernie Bot based on this model. | |
| Claude | 2021.12 | Anthropic | 52 B | 400 billion tokens | Beta | Fine-tuned for desirable behavior in conversations. | |
| GLaM | 2021.12 | 1.2 T | 1.6 trillion tokens | 5600 | Proprietary | Sparse mixture of experts model; more expensive to train but cheaper to run inference. | |
| Gopher | 2021.12 | DeepMind | 280 T | 300 billion tokens | 5833 | Proprietary | |
| LaMDA | 2022.1 | 137 B | 1.56T words, 168 billion tokens | 4110 | Proprietary | Specialized for response generation in conversations. | |
| GPT-NeoX | 2022.2 | EleutherAI | 20 B | 825 GiB | 740 | Apache 2.0 | Based on the Megatron architecture. |
| Chinchilla | 2022.3 | DeepMind | 70 B | 1.4 trillion tokens | 6805 | Proprietary | Reduced-parameter model trained on more data; used in Sparrow bot. |
| PaLM (Pathways Language Model) | 2022.4 | 540 B | 768 billion tokens | 29250 | Proprietary | Aimed to reach the practical limits of model scale. | |
| OPT (Open Pretrained Transformer) | 2022.5 | Meta | 175 B | 180 billion tokens | 310 | Non-commercial research | GPT-3 architecture with adaptations from Megatron. |
| YaLM 100B | 2022.6 | Yandex | 100 B | 1.7TB | Apache 2.0 | English-Russian model based on Microsoft's Megatron-LM. | |
| Minerva | 2022.6 | 540 B | 38.5B tokens from webpages and papers | Proprietary | LLM trained for solving mathematical and scientific questions. | ||
| BLOOM | 2022.7 | Large collaboration led by Hugging Face | 175 B | 350 billion tokens (1.6TB) | Responsible AI | Essentially GPT-3 but trained on a multi-lingual corpus. | |
| Galactica | 2022.11 | Meta | 120 B | 106 billion tokens | CC-BY-NC-4.0 | Trained on scientific text and modalities. | |
| AlexaTM (Teacher Models) | 2022.11 | Amazon | 20 B | 1.3 trillion | Proprietary | Bidirectional sequence-to-sequence architecture. | |
| LLaMA (Large Language Model Meta AI) | 2023.2 | Meta | 65 B | 1.4 trillion | 6300 | Non-commercial research | Trained on a large 20-language corpus for better performance. Researchers fine-tuned Alpaca based on LLaMA weights. |
| GPT-4 | 2023.3 | OpenAI | Exact number unknown | Unknown | Unknown | Proprietary | Available for ChatGPT Plus users and used in several products. |
| Cerebras-GPT | 2023.3 | Cerebras | 13 B | 270 | Apache 2.0 | Trained with Chinchilla formula. | |
| Falcon | 2023.3 | Technology Innovation Institute | 40 B | 1 trillion tokens | 2800 | Apache 2.0 | Training cost around 2700 petaFLOP-days, 75% that of GPT-3. |
| BloombergGPT | 2023.3 | Bloomberg L.P. | 50 B | 363 billion token dataset | Proprietary | LLM trained on financial data, outperforms existing models on financial tasks. | |
| PanGu-Σ | 2023.3 | Huawei | 1.085 T | 329 billion tokens | Proprietary | ||
| OpenAssistant | 2023.3 | LAION | 17 B | 1.5 trillion tokens | Apache 2.0 | Trained on crowdsourced open data. | |
| Jurassic-2 | 2023.3 | AI21 Labs | Exact size unknown | Unknown | Proprietary | Multilingual. | |
| PaLM 2 (Pathways Language Model 2) | 2023.5 | 340 B | 3.6 trillion tokens | 85000 | Proprietary | Used in Bard chatbot. | |
| Llama 2 | 2023.7 | Meta | 70 B | 2 trillion tokens | Llama 2 license | Successor of LLaMA. | |
| Falcon 180B | 2023.9 | Technology Innovation Institute | 180 B | 3.5 trillion tokens | Falcon 180B TII license | ||
| Mistral 7B | 2023.9 | Mistral | 7.3 B | Unknown | Apache 2.0 |
Source: Wikipedia
Listed Companies
- Bard
BARD, a revolutionary language model by Google, boasts an impressive 1.6 trillion parameters, enabling highly precise and contextually relevant text generation. It excels in providing scientifically accurate explanations and reasoning capabilities, thanks to its diverse training corpus from scientific manuscripts, research papers, books, and articles. BARD's specialized knowledge makes it a potent tool for tasks in the scientific domain.
Through its dedicated API, developers and researchers can seamlessly integrate BARD into various applications and platforms. Beyond text, BARD processes multimodal inputs, enhancing comprehension and responses, and supports multiple languages, making it adaptable to diverse linguistic contexts.
- LaMDA / PaLM 2
Google's LaMDA has attracted substantial attention from mainstream observers, rivalling the level of interest seen with GPT-3. LaMDA operates in a manner similar to its primary competitor, albeit with fewer parameters, totalling 137 billion compared to GPT-3.5's 175 billion, which was employed in ChatGPT's training.
LaMDA served as the foundation for Google's chatbot competitor, Bard, which is presently undergoing testing for search functionality with select users. However, in response to the rapidly evolving landscape of LLM development, Google has elevated Bard to operate on PaLM 2, a significantly more advanced framework featuring over 340 billion parameters.
Table 9. Comparison: OpenAI vs Google
| Main Competition Between OpenAI and Google in Recent Years | |
|---|---|
| Round 1: BERT outperformed GPT-1 due to its bidirectional nature, allowing contextual analysis, whereas GPT, being unidirectional, lack this contextual capability and could only utilize preceding text. | |
| - In June 2018, OpenAI released the 117 million parameter GPT-1 model, using a two-step process of pretraining and fine-tuning, setting the stage for future models. | - In June 2017, Google introduced the 65 million parameter Transformer model, a seminal moment in large language models. - In October 2018, Google presented BERT (Bidirectional Encoder Representation from Transformers) with 300 million parameters, outperforming GPT-1 due to its bidirectional nature. |
| Round 2: T5 won by a wide margin, with Google still in the lead. | |
| - In February 2019, OpenAI launched GPT-2 with 1.5 billion parameters, raising concerns about its potential misuse. - In 2019, OpenAI's VP, Dario Amodei, and his team parted ways, founding Anthropic Lab and creating Claude. |
- In October 2019, Google introduced T5 (Transfer Text-to-Text Transformer) with 11 billion parameters, setting a new NLP SOTA. |
| Round 3: The industry was still more accepting of Google's large models. | |
| - In May 2020, OpenAI unveiled GPT-3 with a whopping 175 billion parameters, showcasing the power of large-scale models. - In January 2021, OpenAI introduced DALL-E, bridging text and image generation. - In June 2021, OpenAI and GitHub jointly released GitHub Copilot, powered by a 12 billion parameter Codex. - In March 2022, OpenAI released InstructGPT, highlighting the benefits of a 1.3 billion parameter model. - In July 2022, OpenAI unveiled DALL-E 2. |
- In January 2021, Google debuted the Switch Transformer with 1.6 trillion parameters, superseding GPT-3. - In May 2021, Google showcased LaMDA (Language Model for Dialogue Applications) with 137 billion parameters. |
| Round 4: OpenAI's GPT-4 leads the way, but the model has become more closed off, accessible primarily through its API, raising concerns about transparency. | |
| - In November 2022, OpenAI launched ChatGPT with around 200 billion parameters, a specialized conversational model. - In January 2023, Microsoft deepened its partnership with OpenAI, investing around $10 billion, valuing OpenAI at $290 billion. - In March 2023, OpenAI released GPT-4, with undisclosed parameters but eight times the token capacity of GPT-3, supporting multimodal input. |
In February 2023, Google introduced Bard, a conversational AI system built on LaMDA, akin to ChatGPT. |
Meta
- LLaMA
Meta AI unveils LLaMA (Large Language Model Meta AI), a versatile LLM with 65B parameters. It was unintentionally made open-source, providing research flexibility but raising security concerns. Committed to AI advancement, Meta AI, formerly Facebook AI Research, offers open-source tools for collaborative research. LLaMA, trained on 20 languages, includes models of 7B, 13B, 33B, and 65B parameters. Remarkably, LLaMA-13B surpasses GPT-3 (175B), and LLaMA-65B competes with PaLM-540B, showcasing superior performance. Leveraging the transformer architecture and 1.4 trillion tokens of training data, LLaMA excels in understanding intricate language patterns.
Salesforce – CTRL
Salesforce's Conditional Transformer Language Model (CTRL), a formidable NLP model with 1.6B parameters, excels in precise text generation and control. It stands out with its capacity to attribute data sources to generated text, aiding analysis. Utilizing over 50 control codes, CTRL empowers users to finely control content and style, reducing randomness. Moreover, CTRL's adaptable nature has the potential to enhance various NLP applications through fine-tuning or leveraging its learned representations.
Databricks - Dolly
Dolly, developed by Databricks, is a practical 12B parameter LLM based on Pythia. It excels at following instructions, covering various domains like brainstorming, QA, and summarization. Dolly 2.0, an open-source model, offers ChatGPT-like interactivity, fine-tuned on a high-quality dataset. Databricks provides the entire package, including code, data, and model weights, allowing commercial use without external data sharing. The 15,000-pair training dataset is available for modification and commercial applications. While not state-of-the-art, Dolly serves specific instruction-following tasks effectively.
pen Source Communities
- Hugging Face - Transformers library
Hugging Face is a company specializing in natural language processing (NLP) technologies. It has played a significant role in advancing the Transformers library, a resource offering pre-trained models for a wide range of NLP tasks, including question answering and translation. Established in 2016 by Clément Delangue, Thomas Wolf, and Julien Chaumond, Hugging Face has steadily made remarkable strides in the field since its inception.
- BLOOM (BigScience)
BLOOM (BigScience Large Open-science Open-access Multilingual Language Model) is a massive self-regressive model developed by over 1,000 AI researchers. It aims to provide a large-scale language model for public access. Trained on 366 billion tokens from March to July 2022, it competes with OpenAI's GPT-3, boasting 1.76 trillion parameters. BLOOM uses a decoder-only transformer architecture and has successors like Firefly, BELLE, and TigerBot.
Startup Companies
OpenAI - GPT
OpenAI has released influential language models like GPT-3 and GPT-4, shaping the AI landscape. These models excel in various language tasks, offering customizable features through APIs. OpenAI's pioneering use of Reinforcement Learning from Human Feedback (RLHF) improves model behavior in chat contexts. Their consistent top-tier performance makes them invaluable in research and development.
Figure 8. The Evolution of Large Language Models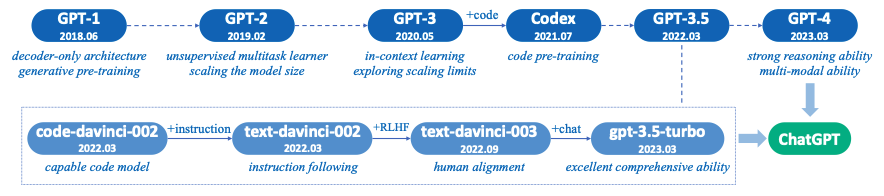 Source: “A Survey of Large Language Models”
Source: “A Survey of Large Language Models”
OpenAI's GPT-4 pricing:
Gpt-3.5: $0.002 per 1000 tokens for both input and output.
Gpt-4–8k: $0.03 per 1000 tokens for input and $0.06 per 1000 tokens for output.
Gpt-4–32k: $0.06 per 1000 tokens for input and $0.12 per 1000 tokens for output.
Anthropic – Claude
Anthropic, founded by former OpenAI experts, rivals ChatGPT with Claude. Claude employs "constitutional AI" and adheres to predefined principles, setting it apart. Google's $300 million investment for a 10% stake mirrors Microsoft's involvement with OpenAI. Anthropic is a key figure in AI ethics and development, emphasizing safety and value alignment. Claude, their versatile language model, excels in text processing and natural conversations, offering extensive general knowledge, multilingual abilities, and automation. It introduces constitutional AI, enabling precise control over AI behaviour.
Cohere
Cohere, a prominent AI company, offers two key language models: command-xlarge (6 billion parameters) and command-medium (50 billion parameters). These models excel in handling instruction-like prompts, making them ideal for chatbots. Cohere's LLMs are geared toward content generation, summarization, and search, with a focus on enterprise-scale operations and data security. They provide a user-friendly API, supporting semantic search, text summarization, generation, and classification in over 100 languages. Cohere also offers the Cohere Playground, simplifying model testing through a code-free visual interface.
AI21 – Jurassic-2
AI21, an Israeli startup, challenges OpenAI effectively. In 2021, they unveiled Jurassic-2, a large language model with 178 billion parameters, slightly surpassing GPT-3.5. In March 2023, they prioritized performance over size, claiming even the smallest Jurassic-2 outperforms its predecessor's largest version. Jurassic-2 includes a grammatical correction API and text segmentation features.
AI21 studio allows users to train their own LLM versions with just 50-100 examples, granting exclusive access. Notably, AI21 used Jurassic-1 and Jurassic-2 to enhance its WordTune Spices chatbot. It sets itself apart from ChatGPT with live data retrieval and source citations, addressing accuracy and plagiarism concerns in a competitive field.
Stability AI - StableLM
StableLM is an open-source language model created by Stability AI. It's trained on "The Pile," a substantial dataset composed of over 20 smaller datasets, totaling 825 GB of natural language data. This model offers lightweight language generation capabilities suitable for various applications.
The Outlook of Large Language Models
Future Advancements in LLMs
ChatGPT, for example, already surpasses GPT-3.5 with context lengths exceeding 10,000 tokens. Future enhancements can potentially scale this to hundreds of thousands or even millions of tokens through techniques like efficient attention and recursive encoding. Current models haven't reached their size limit, and models of greater scale are achievable. Likewise, the volume of training data, including human feedback, continues to grow. In terms of multimodal processing,** videos can expand the training dataset by two orders of magnitude. This allows for linear scaling of existing capabilities and the emergence of new ones. For example, exposure to diverse visual and algebraic content might lead to spontaneous learning of analytical geometry. In addition, existing models excel in humanities but lag in scientific domains. It is feasible for fine-tuning for specialization, transferring skills from one domain to another, even at the cost of some general capabilities and without extensive scaling. For instance, bolstering humanities proficiency to expert level while trading off scientific prowess.
Table 10. LLM Influence Forecast on Generative AI market
| Timeline | LLM Influence and Trends |
|---|---|
| Short-term 2023-2025 | - Enhanced fine-tuning and optimization of Large Language Models (LLMs) across various applications, resulting in more precise and context-aware text generation. - Integration of text-based Generative AI with other modalities like images and videos, addressing diverse market needs. |
| Mid-term 2026-2028 | - Increasing specialization of Generative AI models for specific domains, tailoring AI-generated content to industries and niches within the LLM market. - Users gaining fine-grained control over style, tone, and other attributes, enhancing versatility for the expanding LLM market. - Designing Generative AI models for seamless integration with commonly used software and platforms across industry verticals. |
| Long-term 2029-2030 | - Emergence of fully autonomous Generative AI systems capable of generating content across various domains, including art, music, and literature. - Growing utilization of Generative AI in discovery and material design as researchers explore new technological possibilities. - Establishment of ethical guidelines for the responsible and safe use of Generative AI across diverse applications within the LLM market and the Generative AI ecosystem. |
Challenges
Current evaluation datasets for large models are often limited and don't represent real-world complexity. We need diverse, real-world datasets to ensure models can handle real-world challenges effectively. In terms of ethical alignment, ensuring that large models align with human values and don't reinforce harmful behavior is crucial. Addressing ethical concerns is vital to prevent potential disasters.
In addition, large model research must prioritize security. This includes enhancing model interpretability and supervision to eliminate security risks. Security should be an integral part of model development. What’s more, whether model performance will continue to improve with larger sizes remains uncertain. Our understanding of large models is limited, and gaining fundamental insights is valuable.
Investment Insights
- Companies with Strong Model Training Capabilities: Consider allocating investments to companies that possess robust and sustained capabilities in the development of large language models (LLMs). Such companies, when they leverage their models to create applications, enjoy substantial technological barriers and a competitive edge over those relying solely on third-party LLMs.
- Multimodal Directions: Explore investment prospects in companies diversifying into multimodal applications after establishing a strong foundation in LLM development.
- Multimodal applications encompass the processing of various types of media data, including text, images, audio, and more.
- Investing in this area may yield innovative applications and technologies that cater to a wide range of industry needs, building upon the solid groundwork laid by LLM capabilities.
- Cost-Advantaged Companies: Companies with cost competitiveness may present attractive opportunities in the market, especially for enterprise clients seeking large-scale deployments.
- Identify companies that excel in effectively controlling and reducing deployment costs associated with large language models.
- Consider enterprises with advantages in GPU resource management, model precision optimization, and cost-efficient infrastructure solutions.