AI Image Generators
Emerging Trends for Visual Content Creation
The history of AI art dates back to the 1960s when the early pioneers began exploring the potential of computers to create art. With the rapid growth of deep learning and neural networks, Generative Adversarial Networks (GANs) laid a strong foundation in AI image processing in 2014. AI image generators have gained immense popularity since 2022 when generative AI was released to the public. The five prominent names in this field, including Runway, DALL·E 2, Midjourney, Stable Diffusion, and Bing Image Creator open a new chapter for AI art creation.
In June 2023, Runway Gen-2 brings text-to-video creation to the next level, being the frontier in generative AI after images and texts. Incredibly, several of those text-to-video models are in the research stage, while Runway Gen-2 makes AI video generation commercially available. In addition, Midjourney released version 5.2, introducing exciting updates and features that AI art enthusiasts are experimenting with in creative ways. The update has garnered praise and sparked imaginations within the creative community.
In June 2023, after Inflection AI's successful $1.3 billion investment, Runway, a startup that develops generative AI tools for multimedia content creators, recently revealed an additional $141 million extension to its Series C funding round. Notably, this extension includes contributions from prominent companies such as Google, Nvidia, and Salesforce.
In October 2023, Stability AI announced raising $101 million in a funding round. Coatue and Lightspeed Venture Partners led the round, with O'Shaughnessy Ventures LLC also participating. According to a source from Bloomberg, this funding round values Stability AI at $1 billion after the investment, indicating the company's significant growth.
In February 2023, Deep AI has secured a $1.65 million investment from New GX Ventures SA. New GX Ventures SA is a joint venture consisting of New GX Capital, RMB Ventures, and GIIG Africa. The investment comes after Deep AI emerged as the regional winner for Southern Africa at the African Startup Awards. This funding will support the startup's continued expansion and development of its AI-based solutions.
The Rise of AI Image Generators – Concept and Review
Definition of AI Image Generation
AI image generation refers to the process of using artificial intelligence approach, particularly machine learning algorithms to generate new, original images. It involves training models on large datasets of existing images and using them to produce new images that possess similar characteristics or follow certain styles set by users.
In 2022, notable advancements were made in text-to-image models. These state-of-the-art models began to approach the quality of real photographs and human-drawn art. Text-to-image models typically consist of two main components: a language model and a generative image model. The language model processes the input text and converts it into a latent representation that captures the semantic information. The generative image model then utilizes this representation to produce an image that aligns with the given text.
The progress made by text-to-image models in 2022 reflects the increasing ability of AI to generate images that demonstrate high-quality and artistic characteristics. While these models may not achieve perfection in replicating real photographs or human-drawn art, they have demonstrated significant advancements in generating visually compelling and realistic images based on textual inputs. There are five approaches to AI image generation shown in table 1.
Table 1. AI Image Generation Approaches
| Approach | Description |
|---|---|
| Rule-based generation | This approach involves defining explicit rules and algorithms to generate images based on certain criteria or constraints. The rules can be designed by human programmers or artists, specifying how the image elements should be arranged and combined. |
| Neural network-based generation | Neural networks, particularly generative models like Generative Adversarial Networks (GANs), Contrastive Language-image Pre-training model (CLIP), and diffusion model have been widely used for image generation. These models are trained on large datasets of images and learn to generate new images that resemble the training data. |
| Style transfer | Style transfer techniques use deep learning algorithms to transfer the artistic style of one image onto another. By combining the content of one image with the style of another, the algorithm can generate a new image that exhibits the content and structure of the original image but in the style of the second image. |
| Text-to-image synthesis | AI models can generate images based on textual descriptions or prompts. By training models on paired datasets of text and corresponding images, they learn to generate images that match the given text descriptions. This approach has been used to create AI-generated artworks based on textual prompts. |
| Text-to-video generation | AI model interprets the textual input, understands the desired content, and then generates a video that visually represents the information described in the text. |
A Brief History of AI Art
AI art is fascinating and rapidly evolving. The history of AI art spans from the 1960s to 2023, with significant advancements and developments along the way. In the 1960s and 1970s, early pioneers like Harold Cohen and Versa Molnar began exploring the use of computers to create art, using simple rules and algorithms to generate abstract compositions and geometric shapes. Table 1 displays the milestones of AI art from the 1960s to 2023 (See table 2).
Table 2. The Milestone of AI Art
| Time | Description |
|---|---|
| 1960s – 1970s | Early pioneers like Harold Cohen and Vera Molnar explored the use of computers to create art. They utilized simple algorithms and rules to generate abstract compositions and geometric shapes. |
| 1980s - 1990s | Neural networks and machine learning techniques emerged, opening new possibilities for AI art.Harold Cohen enhanced his program AARON with neural networks, enabling it to produce varied and lifelike artworks.William Latham used machine learning algorithms to generate 3D graphics and animations. |
| 2000s | Deep learning techniques began to revolutionize AI art.Artists and researchers utilized deep learning algorithms to create increasingly realistic and complex artworks.Google's DeepDream project used deep learning to analyze and modify images, resulting in surreal compositions.The Next Rembrandt project used deep learning to generate a new portrait in the style of Rembrandt. |
| 2010s | Generative Adversarial Networks (GANs) were introduced by Ian Goodfellow in 2014, revolutionizing AI art.GANs employed two neural networks, the generator and discriminator, to create and evaluate images.GANs were used to generate entirely new artworks, including the sale of "Portrait de Edmond de Belamy" at Christie's in 2018.AI art gained more prominence and recognition in the art world. |
| 2020 - 2023 | OpenAI's CLIP (Contrastive Language-Image Pretraining) algorithm, developed in 2020, blended natural language processing and computer vision to analyze the relationships between words and images.CLIP enabled the generation of AI art from text prompts, expanding the possibilities of artistic expression.Artists like Katherine Crowson utilized CLIP-powered image generators to make AI art accessible to non-programmers.Diffusion models, such as Latent Diffusion and Stable Diffusion, gained prominence in AI art, offering stability, control, and high-quality image generation. |
In 2014, Ian Goodfellow and their fellows from the University of Montreal introduced a new approach called Generative Adversarial Networks (GANs). This innovation attracted lots of attention from research and practical applications, cementing GANs as the most popular generative AI models in the technology landscape. GANs can generate synthetic images that are visually indistinguishable from real ones. The most famous contemporary artwork (figure 1) made by GANs is "Portrait de Edmond de Belamy". The final price, with premium, was $432,500 - a whopping 4,320 percent rise from the presale high estimate of $10,000.
Figure 1. GANs-made artwork "Portrait of Edmond de Belamy" in 2018 Source: Artnet News
Source: Artnet News
In 2020, OpenAI released its groundbreaking algorithm Contrastive-Image Pretraining (CLIP). This approach has significantly influenced the progress of AI art. CLIP which blends natural language processing and computer vision, allows it to effectively comprehend and analyze the connections between words and images. This has paved the way for text-based prompts for AI image generation.
In 2022, diffusion models, such as Latent Diffusion and Stable Diffusion, gained prominence in AI art (figure 2). These models transformed random noise signals into complex data, offering stability, control, and high-quality image generation. OpenAI's DALL-E and the open-source Stable Diffusion model played significant roles in the mainstream adoption of AI art. Unlike GANs, diffusion models use a continuous process to generate outputs, which makes them more stable and easier to control. In addition, diffusion models offer advantages over GANs in terms of computational cost and performance. In 2022, the Laten Diffusion models took the AI art world by storm, with OpenAI's DALL-E playing a major role in its adoption. In August 2023, Stability AI also made a significant contribution to the art world. With cooperation from HuggingFace, CoreWeave, Stability AI boosts performance comparable to OpenAI DALL-E.
Figure 2. "Théâtre D'opéra Spatial" Generated by Midjourney in 2022“  Source: Midjourney
Source: Midjourney
Deep Learning Models Concepts
Generative Adversarial Network
GANs consist of two neural networks, which are generator and discriminator, trained in alternating periods. The generator network learns to generate synthetic data that mimics the distribution of real data, while the discriminator network learns to distinguish between the generated data and the real data (figure 3). The training process is iterative, and the generator is trained to create images that can fool the discriminator. The discriminator improves its ability to distinguish between real and fake data. The term "adversarial" comes from the concept that networks compete against each other which resembles a zero-sum game.
The generator neural network takes a random input vector, often referred to as a latent vector or noise, as its input. This latent vector is usually sampled from a simple probability distribution, such as a Gaussian distribution. The generator's task is to transform this latent vector into a synthetic sample that resembles the real data it is trying to generate, such as images or text. While the discriminator neural network acts as a binary classifier. It takes an input sample, which can be either a real sample from the training dataset or a generated sample from the generator, and its task is to determine whether the input is real or fake. In the case of image generation, the discriminator determines if an image is from the real dataset or produced by the generator.
During training, the generator and discriminator networks are trained in an adversarial manner. The generator aims to generate samples that can deceive the discriminator into classifying them as real, while the discriminator strives to correctly classify between real and generated samples. This adversarial training process involves iteratively updating the weights and biases of both networks to improve their performance.
As training progresses, the generator learns to produce more realistic samples that make it difficult for the discriminator to distinguish between real and generated data. Meanwhile, the discriminator becomes more skilled at differentiating between real and fake samples. Ideally, this leads to a balanced state where the generator produces high-quality, realistic data, and the discriminator becomes progressively less accurate in distinguishing between real and generated data. The interplay between the generator and discriminator in GANs creates a competitive and cooperative dynamic, driving the model toward generating increasingly convincing and realistic samples.
Figure 3. Generative Adversarial Network Architecture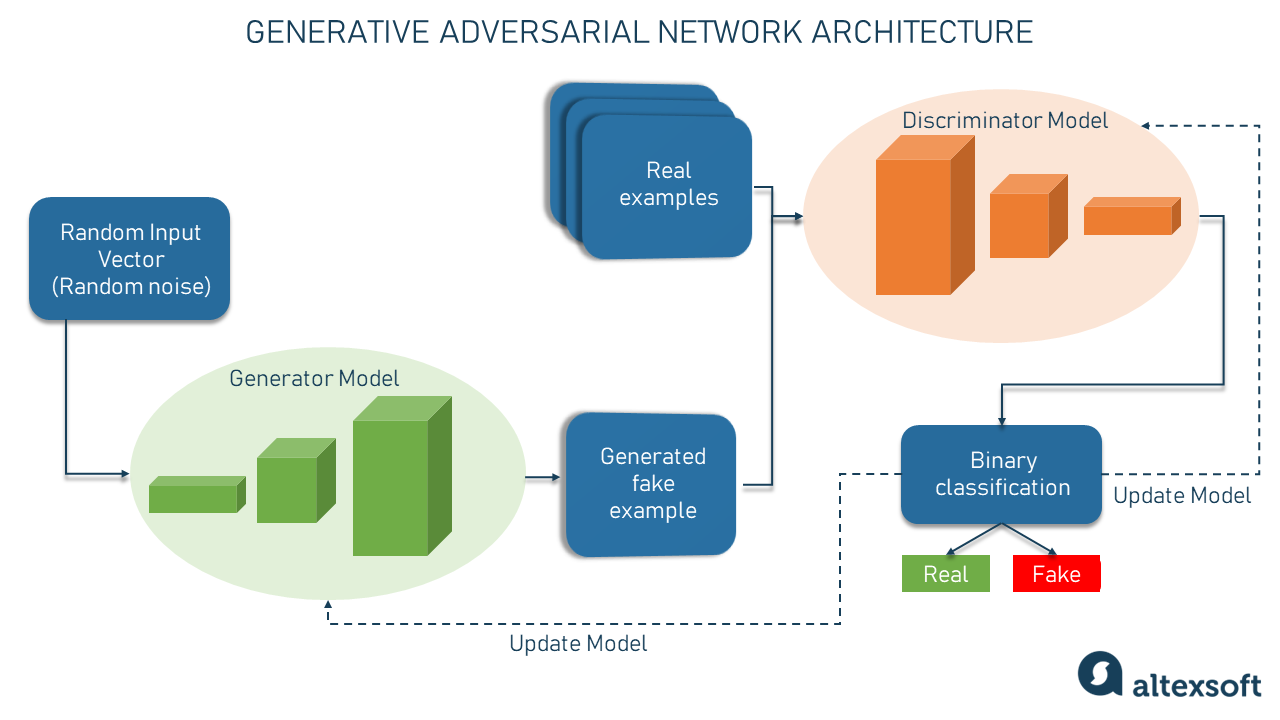 Source: AltexSoft
Source: AltexSoft
Contrastive Language-Image Pretraining
Contrastive Language-Image Pretraining (CLIP) is a deep learning model developed by OpenAI (figure 4). This model is designed to understand and connect images and their textual descriptions in a multimodal approach. Unlike traditional models that solely focus on images, CLIP learns to associate images and text by training large-scale image-text pairs. CLIP has been trained on a large-scale dataset consisting of 400 million image-text pairs, where the captions were scraped from the Internet. By training the model on such a diverse and extensive dataset, CLIP learns to capture the relationships between images and their corresponding textual descriptions. CLIP uses a convolutional neural network (CNN) as its vision encoder. The vision encoder processes images and extracts visual features from them. The architecture of the vision encoder is based on the widely used ResNet-50 convolutional network. CLIP incorporates a Transformer-based language encoder. The language encoder processes textual descriptions and encodes them into a meaningful representation. It captures the semantic information and context of the text, enabling cross-modal understanding.
The contrastive loss function used during training encourages the model to project similar image and text pairs closer together in the shared vector space, while pushing apart dissimilar pairs. This enables CLIP to understand the semantic connections between images and text, facilitating tasks like image classification based on textual prompts and text classification based on visual inputs.
Figure 4. CLIP training process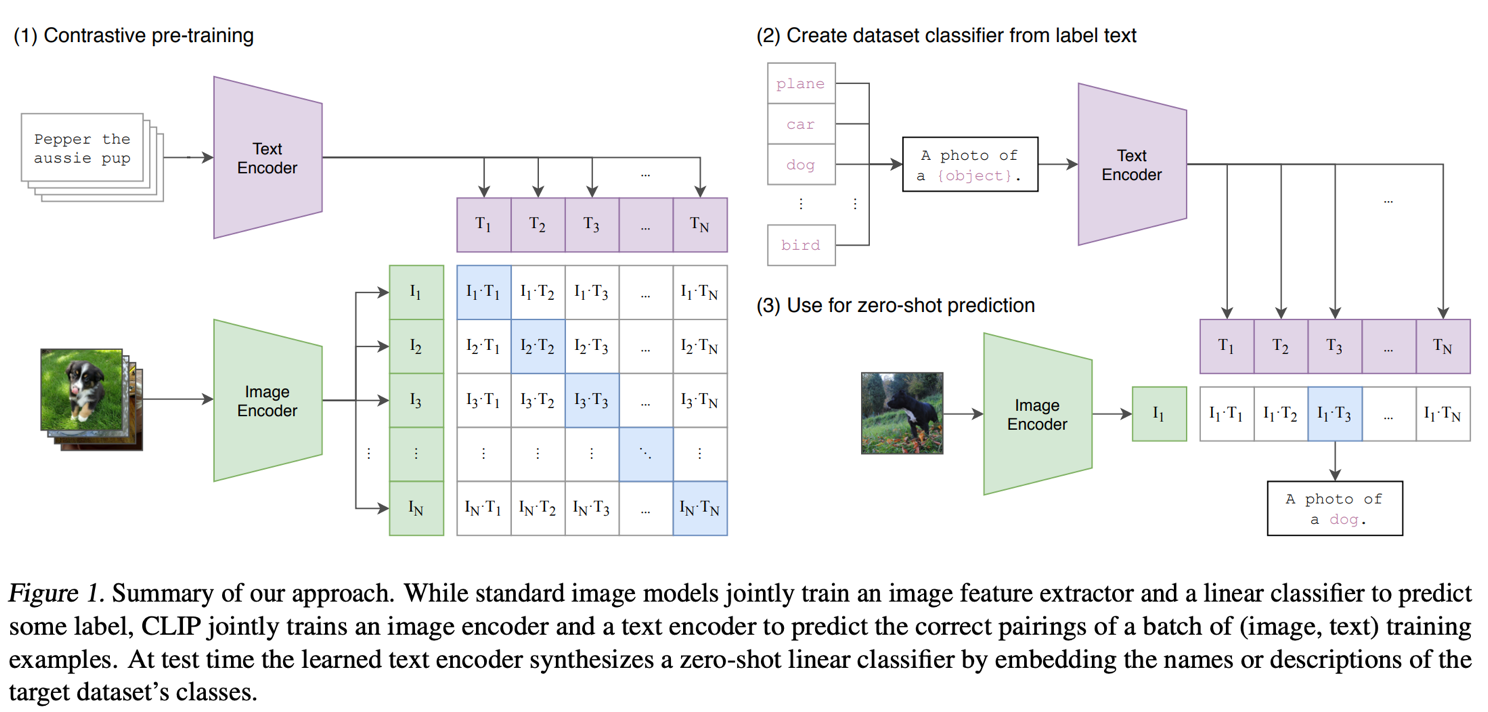 Source: "Learning Transferable Visual Models From Natural Language Supervision."
Source: "Learning Transferable Visual Models From Natural Language Supervision."
Diffusion Model
In diffusion models, the generation process unfolds through a series of diffusion steps using stochastic processes. Each diffusion step involves transforming the current sample towards the desired target distribution while preserving the overall structure and details. The transformations are typically applied gradually, allowing the model to capture the fine-grained details of the data distribution (figure 5).
The core idea behind diffusion models is to model the data distribution as the result of a gradual diffusion process. Starting from a random noise source, the generated samples undergo a series of transformations that gradually reduce the noise level and increase the resemblance to the target distribution. Through these diffusion steps, the model learns to capture the complex dependencies and patterns present in the data.
One popular diffusion model is the Noise-Contrastive Estimation (NCE) diffusion model. It applies a series of invertible transformations to the initial random noise source. These transformations are learned during training and aim to minimize the difference between the generated samples and the target data distribution. By iteratively applying these transformations, the model progressively refines the samples and generates high-quality outputs. Diffusion models have been applied to generate different types of real-world data, and the famous ones are text-conditional image generators like DALL-E and Stable Diffusion.
Figure 5. Diffusion Model Training Process Source: "Diffusion Models: A Comprehensive Survey of Methods and Applications."
Source: "Diffusion Models: A Comprehensive Survey of Methods and Applications."
Models Comparison
In 2021, OpenAI improved the architecture of diffusion models and introduced classifier guidance to enhance sample quality. By finding a better architecture through a series of ablations, they achieved superior sample quality on unconditional image synthesis tasks. Additionally, they further improved sample quality on conditional image synthesis tasks by using classifier guidance, which is a method for trading off diversity for fidelity using gradients from a classifier.
The paper compared their diffusion models to GANs and showed that their models outperformed GANs on high-resolution ImageNet synthesis tasks. They achieved an FID (Fréchet Inception Distance) of 2.97 on ImageNet 128x128 and 4.59 on ImageNet 256x512, matching the performance of BigGAN-deep even with as few as 25 forward passes per sample [9]. The diffusion models also demonstrated better coverage of the distribution compared to GANs. The improvements in architecture and the incorporation of classifier guidance allowed diffusion models to surpass GANs in terms of image sample quality, making them a promising direction for image generation (figure 6).
Figure 6. Sample quality comparison with state-of-the-art generative models for each task 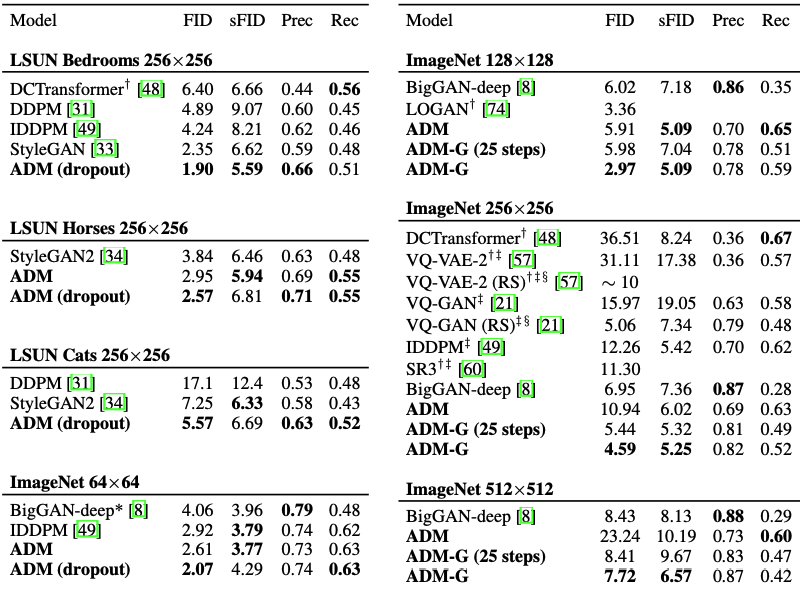 Source: "Diffusion Models Beat GANs on Image Synthesis"
Source: "Diffusion Models Beat GANs on Image Synthesis"
This section illustrated the trending deep learning models in terms of advantages and disadvantages (table 3). Diffusion Model has unique advantages that set them apart from GANs and CLIP. Diffusion Models offer fine-grained control over the generation process, allowing users to manipulate the quality and diversity of the generated data. The networks provide image synthesis and denoise tasks to make realistic samples. The training process is much more stable than GANs. The high-quality images generated by Diffusion Models create more detailed structures. In addition, Diffusion Models have demonstrated exceptional performance and paved the way in various applications, including DALLE-2, Midjourney, Runway and Stable Diffusion. These capabilities have been exemplified by winning artistic awards, with the AI-generated nature of the images only revealed after the fact.
Table 3. AI Image Generator Models Comparison
| Model | Advantage | Disadvantage |
|---|---|---|
| GANs | High-Quality Sample Generation: GANs have the ability to generate high-quality and realistic samples, such as images or text, that closely resemble the training data. | Diversity in Output: GANs can produce a diverse range of outputs by sampling from the latent space. This allows for exploration and generation of novel and creative samples. Training Instability: GANs can be challenging to train as they involve a competitive and adversarial learning process. The generator and discriminator networks need to be carefully balanced, and training can be sensitive to hyperparameters and initialization. Mode Collapse: GANs are prone to mode collapse, where the generator fails to capture the full diversity of the target distribution and instead produces limited variations. This can result in generated samples lacking diversity and creativity. |
| CLIP | Multimodal Understanding: CLIP enables a deep understanding of the relationship between images and text, allowing the model to connect and reason about the two modalities. This facilitates tasks like zero-shot image classification and text-based image retrieval. Generalization and Transfer Learning: CLIP demonstrates strong generalization capabilities and can transfer its understanding to various downstream tasks without extensive fine-tuning. This makes it useful for a wide range of applications. |
Data Dependency: CLIP's performance heavily relies on the quality and diversity of the training data. If the training data is biased or limited, it can impact the model's ability to generalize and understand new inputs accurately. Lack of Fine-Grained Understanding: While CLIP excels at capturing high-level semantic relationships between images and text, it may not capture fine-grained details or specific visual attributes as effectively as domain-specific models. |
| Diffusion Model | Realistic Sample Generation: Diffusion models can generate high-quality and realistic samples by iteratively refining a random noise source. They capture complex dependencies and details of the data distribution, leading to visually appealing outputs. Control over Generation Process: Diffusion models allow for fine-grained control over the generation process by modulating the diffusion steps or incorporating conditioning information. This enables targeted generation and manipulation of specific attributes. |
Computational Complexity: Diffusion models can be computationally expensive to train and generate samples, especially for high-resolution or complex data domains. The iterative nature of the generation process can require significant computational resources. Training Challenges: Training diffusion models can be challenging, as it involves learning complex transformations and managing the trade-off between diffusion steps and enhancing detailed structure. Proper architecture design and training strategies are crucial for achieving good results. |
Trending AI Image Generator Applications
Runway
Runway, the creators of a web-based video editor powered by machine learning, have introduced Gen-2 in March 2023, an advanced AI system capable of generating videos using text, images, and video clips. Gen-2 is a direct update to its predecessor, Gen-1, which was introduced in February 2023. According to the development team, this new system allows users to generate new videos in a realistic and consistent manner. Users can achieve this by applying the composition and style of an image or text prompt to the structure of a source video, a feature that was already present in Gen-1. Alternatively, users can generate videos solely based on text prompts, without the need for any accompanying visual input. New features include: generating stunning visuals and animations, creating realistic 3D models and environment, enhancing images and videos with AI-powered filters, automating time-consuming tasks with intelligent algorithms and develop unique design elements for branding and marketing campaigns (figure 7).
What distinguishes Runway is that the platform is intuitive and user friendly. Creators can easily access a wide range of machine learning models, empowering them to experiment with various algorithms and techniques even without extensive technical knowledge. The platform's drag-and-drop interface and real-time previews facilitate the seamless integration of diffusion models to creative workflows.
Figure 7. Runway Toolkits
- Text + Image to Video
Runway ML has recently introduced an AI-powered text+image-to-video tool on Gen-2, which signifies a significant update to their platform. It allows users to edit and generate videos using natural language descriptions and source image, making the process more intuitive and seamless.
With this new tool, users can import image and input prompts to generate videos. This capability enhances the creation of cinematic videos, giving users more flexibility and creative control over the video production process.
Figure 8. Runway Text + image-to-Video Tool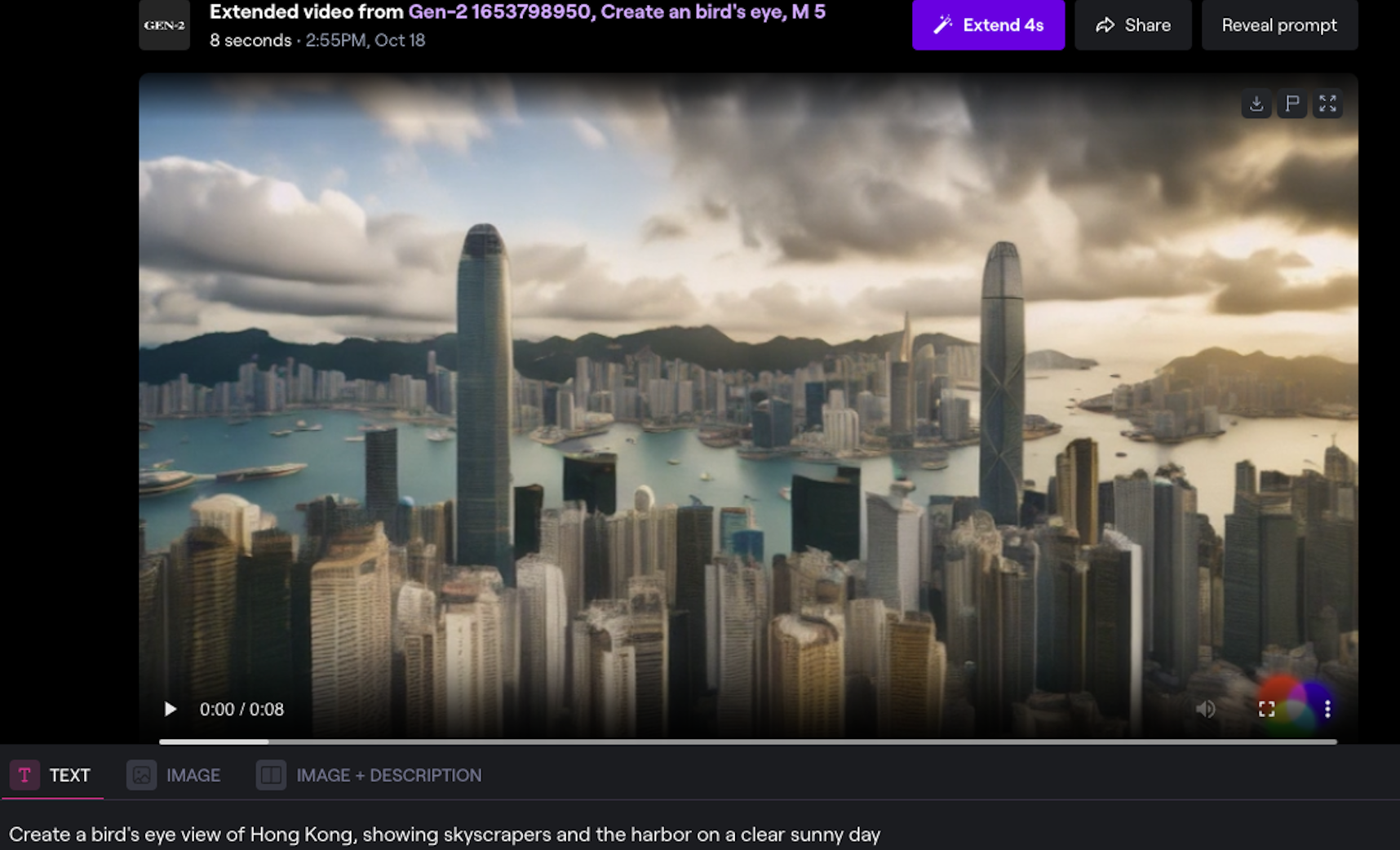
- Stylization
Runway offers a style transfer feature that allows users to apply artistic styles from one image or video to another. Style transfer is a technique that uses deep learning algorithms to extract and transfer the visual style of one image or video (referred to as the style image or video) onto the content of another image or video (referred to as the content image or video).
With Runway style transfer tool, users can select a style image or video and a content image or video, and the AI model will apply the artistic style of the style image or video to the content image or video. This process results in a new image or video that combines the content of the original with the visual style of the selected style image or video (figure 9).
Figure 9. Runway Stylization Tool 
Midjourney
Midjourney is an excellent AI image generator that allows you to create images based on text prompts. The images it generated seem more coherent, with better textures and colors. In particular, the people and objects are more lifelike and natural. The beta version is only accessible through Discord. Unlike other AI image generators, Midjourney generates images through users interacting with Midjourney bot. In the Discord community, you can enter a prompt by typing  . The bot will generate four variations based on your prompts, which you can download, upscale, and re-edit. In the Discord community, images you create are publicly available, which gives everyone the chance to share the inspiration (figure 10).
. The bot will generate four variations based on your prompts, which you can download, upscale, and re-edit. In the Discord community, images you create are publicly available, which gives everyone the chance to share the inspiration (figure 10).
Figure 10. Midjourney Discord 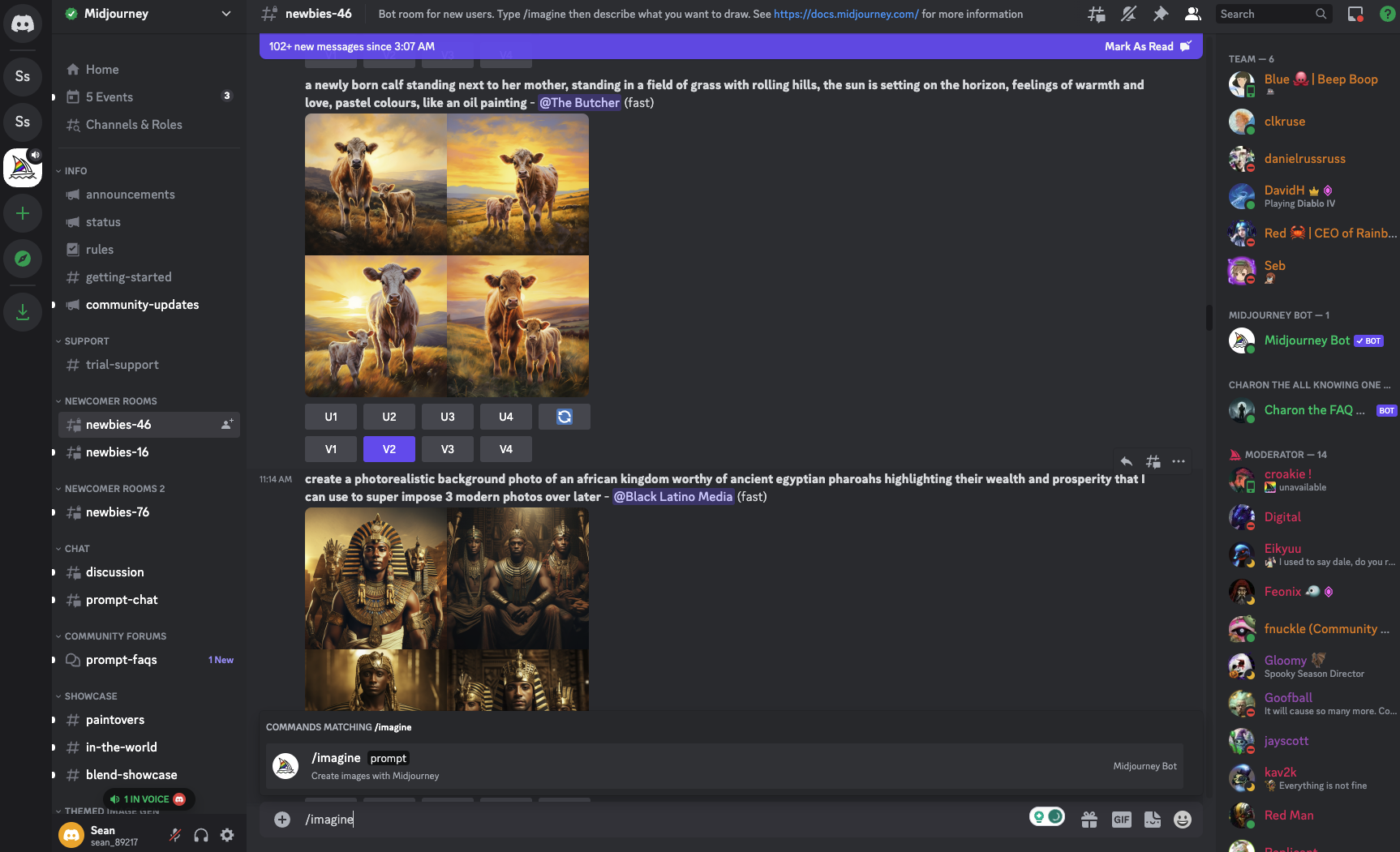
To have precise control over the output of image prompts, you can include additional parameters after "/imagine." These parameters allow you to customize aspects such as aspect ratio, styling level, and more. For instance, by using the prompt "/imagine cats and dogs –q3 –iw 0.25," we instructed Midjourney to generate an image featuring cats and dogs with an image quality set to 3 and an image prompt weight of 0.25. The image prompt weight determines the degree of connection between the generated image and the text prompt. A higher weight produces images closely related to the prompt, whereas a lower weight grants the bot more creative freedom in generating the images (figure 11).
Figure 11. Image Commands to Create Adjust Image Generation 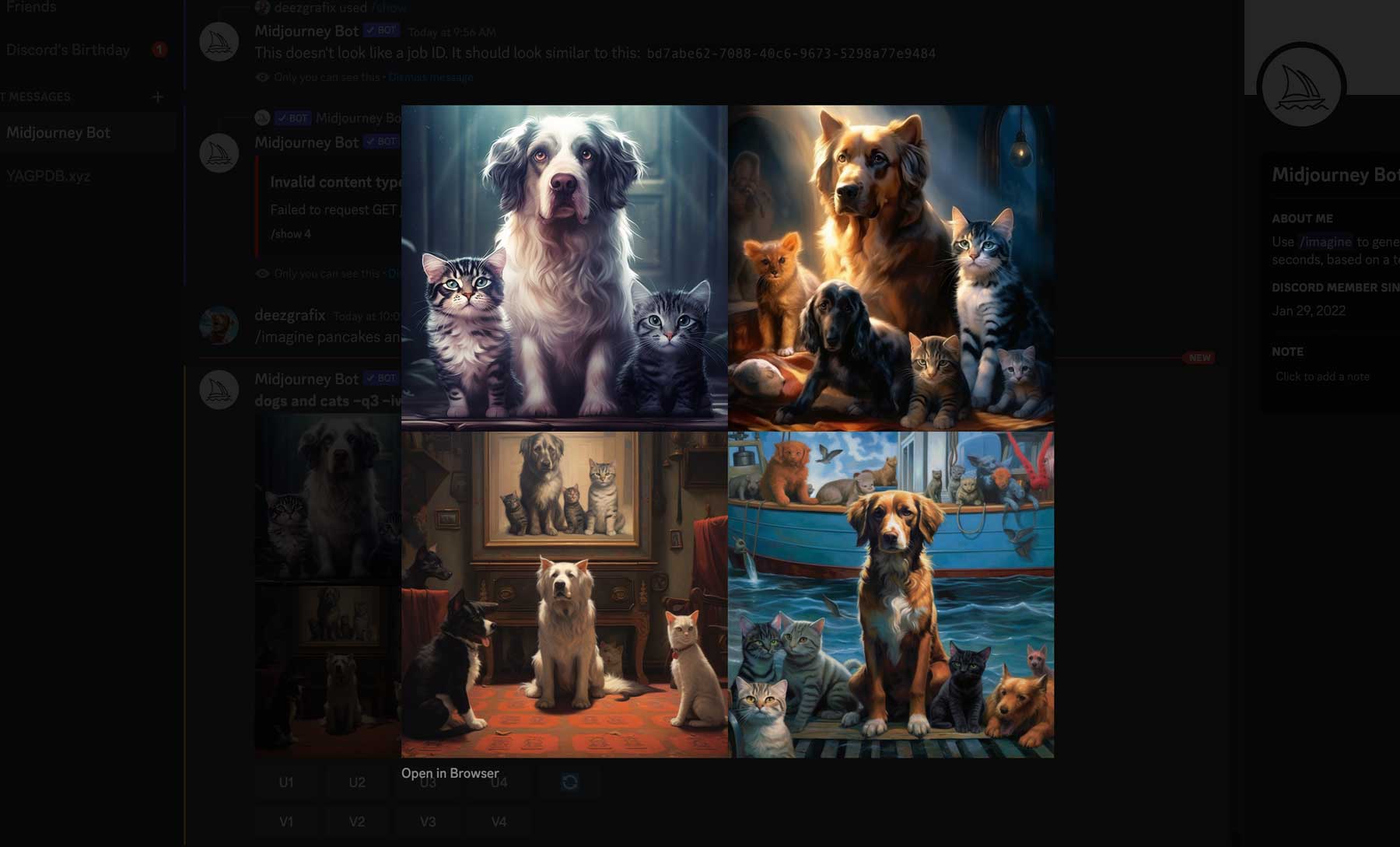 Source: "How to Use Midjourney to Create AI Art in 2023"
Source: "How to Use Midjourney to Create AI Art in 2023"
On 22 June 2023, Midjourney released the latest version 5.2. The latest version comes with some interesting updates and tools that bring AI art lovers a highly creative experience.
- Zoom out tool
The zoom tool enables users to enlarge an initial image, expanding its range to a larger scale while keeping the original image's details. When a prompt is entered using the "/image" command, Midjourney generates four visual iterations arranged in a grid according to the user's input. Users can then select and enhance the specific image they prefer, resulting in a higher level of detail (figure 12).
Figure 12. Midjourney Zoom Out Tool Source: "Midjourney Zoom Out Feature."
Source: "Midjourney Zoom Out Feature."
- Variation Mode
Midjourney V5.2 introduces a new feature called "Variation Mode," which allows users to fine-tune the level of visual nuance and change applied to their outputs. By using the prompt command "/settings," users can select between "High Variation Mode" or "Low Variation Mode." Opting for High Variation Mode results in slightly greater visual divergence from the original output, potentially leading to more interesting and exploratory outcomes. On the other hand, selecting Low Variation Mode promotes greater visual consistency across the outputs (figure 13).
Figure 13. Low Variation Mode (up) and High Variation Mode (bottom)
 Source: Midjourney Variation Mode
Source: Midjourney Variation Mode
- Shorten Command
One useful way to get around this is to use Midjourney's "Shorten" command. Simply type "/shorten" and insert your prompt and Midjourney will analyze its components and suggest a few alternatives for you to use. This function allows users to create precise prompts for accurate image generation (figure 14).
Figure 14. Midjourney Shorten Command
 Source: Midjourney Shorten Command
Source: Midjourney Shorten Command
StabilityAI
Stability AI has released Stable Diffusion XL (SDXL) 1.0 in August 2023, an advanced text-to-image model featured on Amazon Bedrock. This launch marks a significant advancement in the field of text-to-image models. AI art generators, leveraging machine learning algorithms and vast datasets, have gained popularity for their ability to create captivating and dreamlike images. SDXL 1.0 offers enhanced image quality, faster generation speed, and a unique feature allowing fine-tuning with just five images. With a large parameter count, including a 3.5 billion parameter base model and a 6.6 billion parameter model ensemble pipeline, SDXL 1.0 is positioned as a leading open image generation model. Stability AI's collaboration with AWS and the availability of SDXL 1.0 on Amazon Bedrock aim to facilitate the development of innovative generative AI applications. Stability AI has also introduced a developer platform and Stable Doodle, a sketch-to-image tool that gained significant traction with over 3 million images generated within a week of its release (figure 15).
Figure 15. Tools on Stable Diffusion SDXL 1.0 Model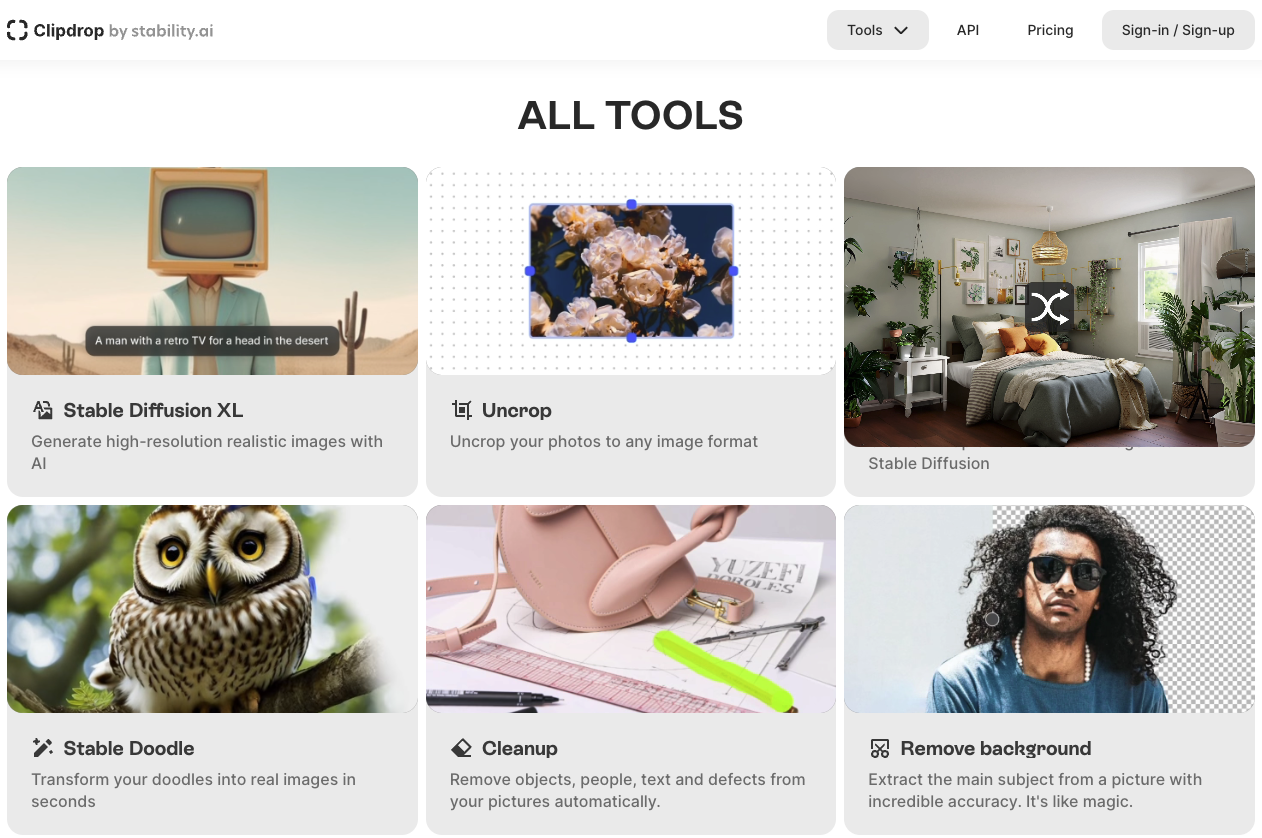
Business Strategy
Business Model
While AI image generators are going viral in the booming market for text-to-image creation, businesses benefit from image creation, such as Runway, Midjourney, Stable Diffusion, DALL-E2, and Imagen that have immersed in the AI image market where they offer high-quality image creation at a lower cost.
Open-Source Software as a Service
Open-source Software as a Service, also known as Open SaaS, refers to a software-as-a-service model where the underlying codebase of the SaaS application is open-source and accessible to users. The source code of the software is freely available, allowing users to view, modify, and redistribute the code according to the terms of the applicable open-source license. Open-source SaaS combines the benefits of cloud-based software delivery (SaaS) with the advantages of open-source software, such as transparency, flexibility, and community collaboration. Users can leverage the SaaS application while also having the ability to customize and extend its functionality to suit their specific needs. The main advantage of open-source AI image generators is that it is much cheaper, and it offers more flexibility and control over the final image.
Commercial Software as a Service
The commercial SaaS model aims to strike a balance between the principles of open-source software and the need for sustainable business practices. The commercial open-source model enables companies to monetize their open-source software by providing value-added services or proprietary extensions. These services may include technical support, consulting, training, customization, maintenance, or hosting. By offering these services, companies can generate revenue while still leveraging the benefits of open-source collaboration and community involvement. For example, StabilityAI, and Google Imagen are open-source, with subscription plans from free of charge to enterprise-level demands (table 4).
Table 4. Top 5 AI Image Generators Business Model
| Company | Open-source? | Price | Advantage |
|---|---|---|---|
| Midjourney | No | From $10/month for ~60 images/month and commercial usage rights | Access via DiscordHigh-quality results High accurate response to text prompts |
| StabilityAI | Yes | 25 free credits for new users; from $10 for 1000 credits | Easy to customize with high-quality results Open-source - users can find-tuned the model |
| DALL-E (OpenAI) | No | From $0.016/image to $0.02/image; $15 for 115 generation increments | Easy to use – simpler promptsAffordable |
| Firefly(Adobe Photoshop) | No | 25 monthly credits for free; $19.99/month as part of the Creative Cloud Photography Plan | Generative Fill – allows users to select and use prompts to replace objects Integrated with Photoshop, bringing industry standard image editor to the next level |
| Imagen(Google) | Yes | From $0.05/photo for individual to customizable commercial usage rights | High image-text alignment More compute efficient, more memory efficient and converges faster |
| Runway | No | From free of charge to $76 for individual/month; Customized enterprise demands | Excellent cohesion of various AI image generation for diverse output Special options include real-time, live video and image synthesis |
Market Landscape
Market Size
The global market for AI image generators was valued at approximately USD 301.7 million in 2022. It is projected to experience a compound annual growth rate (CAGR) of 17.5% from 2023 to 2030 (figure 16). The significant advancements in deep learning and AI algorithms have greatly enhanced the capabilities of AI image generators. The development of neural network architectures, such as (GANs), CLIP and Diffusion Models, has enabled the generation of high-quality and realistic images. As these algorithms continue to progress, the potential applications of AI image generators expand, thereby driving the growth of the market. The digital age has created a substantial demand for visual content across multiple industries, including advertising, marketing, media, and entertainment.
In 2022, the software segment of the AI image generator market dominated with a revenue of approximately USD 140 million. This segment is expected to surpass USD 650 million by 2032, according to Grand View Research. The increasing demand for high-quality images across various purposes is a key driver behind this growth. Businesses, particularly those in the e-commerce sector, require high-definition images to showcase their products and attract customers effectively. The film and gaming industries also rely on AI-powered image generators to create realistic special effects and backgrounds. Furthermore, there is a growing need for visually appealing images on social media platforms and websites to enhance user engagement. This increasing demand for AI image generator software is fueling the market's expansion.
Figure 16. Global AI Image Generator Market Size by Component, 2021 to 2032 (USD Million)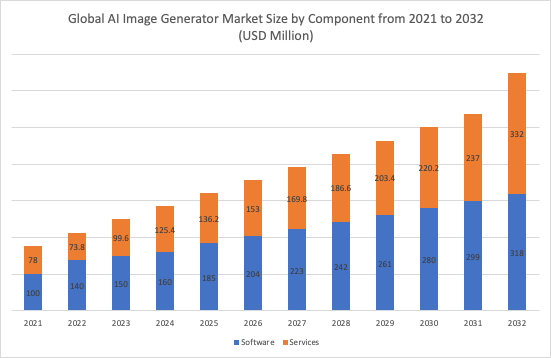 Source: "AI Image Generator Market Size, Share Analysis Report 2032"
Source: "AI Image Generator Market Size, Share Analysis Report 2032"
In 2022, the media and entertainment industry held a significant market share of 26.6% in the AI image generator market (figure 17). By 2032, it is projected to reach a value of USD 250 million. This growth is driven by the capabilities of AI image generators to efficiently produce high-quality visual content, streamline creative processes, and provide innovative solutions for visual storytelling. AI-powered tools in this industry empower content creators with time and cost-effective options to generate diverse and engaging visuals, enhance visual effects, and explore new creative possibilities. These tools serve as valuable assets in the competitive landscape of content creation and digital media.
Figure 17. Global AI Image Generator Market Share by End-User in 2022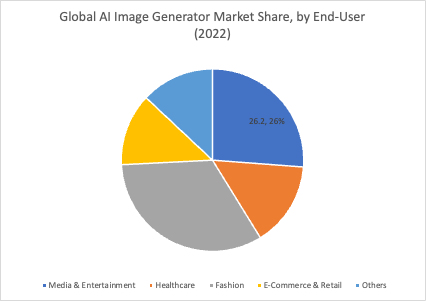 Source: "AI Image Generator Market Size, Share Analysis Report 2032"
Source: "AI Image Generator Market Size, Share Analysis Report 2032"
In 2022, the North American market for AI image generators was valued at approximately USD 70 million, dominating the revenue share of 36.0% in the world. It is expected to exceed USD 300 million by 2032. This growth can be attributed to the potential of AI image generators to bring about revolutionary changes in various industries, including media, advertising, and e-commerce. Companies such as Adobe, NVIDIA, and OpenAI are actively involved in the development and promotion of AI-powered image creation tools. As a result, businesses in North America are increasingly adopting these solutions to maintain a competitive edge. Additionally, the region's strong research institutions and tech-driven culture create an environment conducive to the development and adoption of cutting-edge AI technologies, further driving the popularity of AI image generators in the North American market.
Market Trend
As a survey conducted by Yahoo Finance, the research was to identify the top five AI image generators to try in 2023. The research involved analyzing reputable sources such as software rating websites, discussion forums, expert reviews, and professional recommendations. We evaluated each AI image generator based on criteria such as user interface, features, user reviews, image quality, output variety, ease of use, speed, compatibility, customer support, and pricing options. To cater to different user needs, we considered both free and paid options. The rankings were determined by assigning scores on a scale of 1 to 5, and the final list was ordered in ascending order based on the weighted scores and collective evaluation across different sources (table 5).
Table 5. Top 10 AI Image Generators in 2023
| Application | Score | Highlights |
|---|---|---|
| Fotor | 4.2 | It's free to use, making it an attractive option for users seeking cost-effective AI image generation. However, the free version restricts users to generating only 10 images per day. |
| PhotoSonic | 4 | PhotoSonic can accept complex and lengthy prompts, enabling users to request the generation of a wide range of images. Utilizing latent diffusion, the AI takes noisy input images and transforms them to align with the given prompt. |
| Starry AI | 3.9 | With its efficient AI image creation capabilities, StarryAI has established itself as one of the top AI art generator apps in the market. |
| Leap AI | 3.8 | Leap AI is a versatile platform that enables users to generate a wide range of images, including art, avatars, and logos. |
| Dream by WOMBO | 3.7 | Dream by WOMBO is an AI-based website and mobile app that allows users to create and modify images in various styles, including realistic, mystical, vibrant, and dark fantasy. |
| CanvaAI | 3.6 | This new addition seamlessly integrates with Canva's existing features. This allows users to incorporate AI-generated art into a variety of projects, ranging from social media posts to birthday cards. |
| Bing Image Creator | 3.5 | Bing Image Creator, a collaboration between Microsoft and OpenAI, harnesses the power of DALL·E 2 to provide users with a free generative AI model for image creation. Bing Image Creator offers default styles that may differ from what users are accustomed to. |
| Pixray | 2.9 | Pixray is a user-friendly AI image generator available in various forms: as a website, for local installation on a PC, and even as an API suitable for creating AI art Discord bots. Pixray operates on a different model than services like DALL-E or NightCafe. |
| Shutterstock AI Image Generator | 2.8 | Shutterstock powered by DALL·E 2, has the option to choose between a Standard license and an Enhanced license, which affects the pricing structure based on their licensing needs. |
| Runway | 2.7 | Users can generate up to 500 images using the AI system. Notably, Runway allows for fine-tuning of the generated images by adjusting settings such as style, resolution, mood, medium, and prompt weight. |
Market Map
AI image generators play an important role in the whole multimodal generative AI landscape (figure 18). AI image generators hold significant importance in the broader multimodal generative AI landscape. They contribute to the generation of visual content and play a crucial role in the synthesis, manipulation, and transformation of images. Here are some key reasons why AI image generators are essential in the multimodal generative AI landscape:
As society grapples with the growing controversy surrounding artificial intelligence, its presence in the arts and mainstream media is also expanding. Remarkably, the top AI generators in 2023 can produce highly detailed and accurate artwork that can easily be mistaken for real creations. Creating these artworks is surprisingly straightforward for users, as many of the leading AI art generators only require a simple worded prompt in the style such as Runway and Midjourney to generate paintings, sketches, or even lifelike photographs.
Figure 18. AI Image Generator Market Segment 
The landscape of AI image generators encompasses a variety of algorithms and large language models that contribute to the generation and manipulation of images (figure 19). As the Diffusion Models shape the AI image landscape, we have witnessed that many open-source variants have been commercialized such as StabilityAI, Midjourney, DALL-E, and Google Imagen. Image dataset providers such as ImageNet, LSUN and CIFRA-10 provide the source for model training and fine-tuning.
Large language models, as the bridge that connects the functions and base LLMs and AI image applications. These applications provide an all-in-one solution for multi-modal use cases, such as text-to-image, text-to-video and video-to-3D generation. Regarding AI image applications, we can see text-to-image is dominating the market with many startups such as Runway, Midjourney and StabilityAI rising and competing for the application scenarios and image variations and quality. We also witness that Runway is a frontier of text-to-video generation, taking market advantage of video generation.
AI image generation has a wide range of use cases across various industries such as entertainment and media, advertising and marketing, fashion and virtual reality, and creativity. AI image generators are extensively used in the entertainment and media industry. They are employed in generating realistic visual effects for films, TV shows, and commercials. These generators can create virtual environments, creatures, and simulations, enhancing the overall visual experience. AI image generators play a crucial role in creating visual content for advertising and marketing campaigns. They can generate high-quality images of products, allowing for virtual try-on experiences, visualizing different styles and variations, and showcasing product features. In terms of the creation of immersive gaming experiences and virtual reality (VR) environments. AI generators can produce realistic characters, landscapes, and objects, enhancing the visual fidelity and realism of virtual worlds. In terms of e-commerce industries. They enable virtual try-on experiences, allowing customers to see how clothing, accessories, or eyewear would look on them before making a purchase. This enhances the online shopping experience and reduces the likelihood of returns. In addition, AI image generators serve as tools for artists, designers, and creative professionals. They can generate visual inspiration, aid in the creative process, and facilitate the exploration of different artistic styles and concepts. AI generators can also assist in generating concept art, illustrations, and digital paintings.
The landscape of AI image generators is evolving rapidly, with ongoing research and advancements in algorithms, architectures, and training techniques. These developments continue to push the boundaries of what is possible in terms of image generation, manipulation, and synthesis, enabling a wide range of applications across various industries.
Figure 19. AI Image Generation Landscape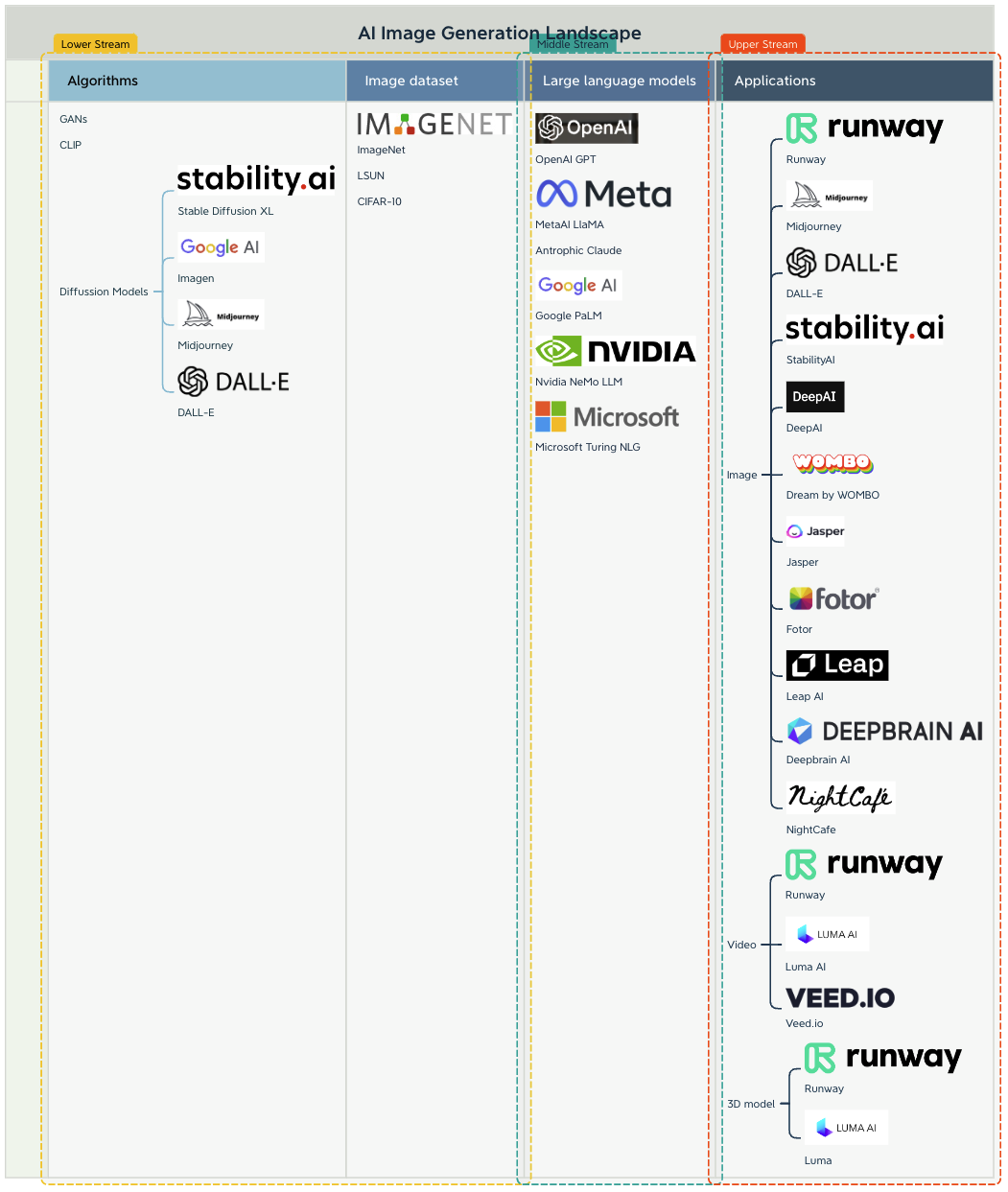
Company Analysis
Summary
It is noticeable that many big technology companies are investing in their own generative AI art solutions, whether through partnerships with startups or in-house R&D. For example, Microsoft teaming up with OpenAI for Bing Image Creator, Google leveraging the R&D team to develop its open-source diffusion model called Imagen, Adobe released Firefly, a toolkit can be integrated into the industry level application such as Photoshop. Apart from this, many startups are in the spotlight. Runway raised $ 141 million in the last funding round in Series C, with a valuation of $1.5 billion. In addition, Midjourney, a 40-member team is projected to generate $200 million in revenue in 2023 from over 15 million community members, without external investors. Stability AI, a London-based startup behind Stable Diffusion, is in discussions to raise $100 million from investors, including a potential deal with Coatue that would value the company at $500 million. Stability AI's prior round of funding was independently verified, and the company has raised at least $10 million at a valuation of up to $100 million. In table 6, the top-funded startups raised $584 million as of October 2023.
Table 6. Top-funded Startups
| Company Name | About | Lead Investors | Last Funding Status | Last Funding Date | Last Funding Amount | Total Funding Amount | Founders | Headquarters Location | Founded Year |
|---|---|---|---|---|---|---|---|---|---|
| DALL·E 2 | DALL·E 2 is an AI system that creates realistic images and art from a description in natural language. | - | - | - | - | - | - | San Francisco Bay Area, West Coast, Western US | 2021 |
| DeepAI | DeepAI is an experimental AI product lab. | - | Seed | Mar 22, 2019 | - | - | Kevin Baragona, Peter Griggs | San Francisco Bay Area, West Coast, Western US | 2017 |
| Fotor | Fotor is a multi-platform photo editing tool. | GF Securities | Early Stage Venture | Sep 20, 2017 | $7.6M | $10.6M | Tony Duan | Asia-Pacific (APAC) | 2009 |
| Jasper | Jasper is an AI writing tool that helps businesses create content. | Insight Partners | Early Stage Venture | Oct 18, 2022 | $125M | $131M | Chris Hull, Dave Rogenmoser, John Philip Morgan | - | 2015 |
| Leap AI | Enabling developers to easily add AI to their apps. | Founders | Seed | Jan 30, 2023 | - | - | Alex Schachne, Claudio Fuentes | San Francisco Bay Area, West Coast, Western US | 2023 |
| Luma AI | Luma AI is to enables everyone to capture and experience the world in 3D. | Amplify Partners | Early Stage Venture | Mar 20, 2023 | $20M | $25.5M | Alberto Taiuti, Alex Yu, Amit Jain | San Francisco Bay Area, Silicon Valley, West Coast, Western US | 2021 |
| Midjourney | Midjourney is a non-profit research lab that is investigating new thought mediums to improve the human species' inventive abilities. | - | - | - | - | - | - | San Francisco Bay Area, West Coast, Western US | 2022 |
| Deepbrain AI | DEEPBRAIN AI provides conversational AI avatars and AI video generator. | IMM Investment, Korea Development Bank | Early Stage Venture | Aug 11, 2021 | $44M | $52M | Eric Seyoung Jang | San Francisco Bay Area, Silicon Valley, West Coast, Western US | 2016 |
| NightCafe | AI Art Generator App | - | - | - | - | - | Angus Russell | Asia-Pacific (APAC), Australasia | 2019 |
| Runway | Runway is an applied AI research company that builds the next generation of creativity tools. | Late Stage Venture | Jun 29, 2023 | $141M | $236.5M | Alejandro Matamala, Anastasis Germanidis, Cristóbal Valenzuela Barrera | Greater New York Area, East Coast, Northeastern US | 2018 | |
| Stability AI | Stability AI is an artificial intelligence-driven visual art startup that designs and implements open AI tools. | Intel Corporation | Seed | Nov 09, 2023 | $50M | $173.8M | Emad Mostaque | Europe, Middle East, and Africa (EMEA) | 2019 |
| WOMBO | WOMBO is an AI-powered lip sync app that creates deepfake copies of images lip-syncing to a selection of songs. | - | Seed | Jan 01, 2023 | - | $6M | Akshat Jagga, Angad Arneja, Ben Zion Benkhin, Parshant Loungani, Paul Pavel, Vivek Bhakta | Great Lakes | 2020 |
| Total Funding | $387.6M | $635.4M | |||||||
Source: Crunchbase
Listed Companies
Microsoft Bing Image Creator
On 3 October 2023, Microsoft announced that OpenAI's latest DALL-E3 model is now available to all users of Bing Chat and Bing Image Creator. The launch began last week, initially for Bing Enterprise users and then for Bing Image Creator, and is now open to everyone.
Interestingly, Bing is getting access to DALL-E 3 before OpenAI's own ChatGPT, which is scheduled to happen later this month but only for paying users. This makes Microsoft's Bing likely to be the most popular image generating tool for a while. DALL-E 3 is the third version of OpenAI's image generating model. According to the company, it has improved its understanding of prompts and is capable of producing more creative and photorealistic images. It is also designed to be user-friendly, and integrated into Bing Chat and ChatGPT, allowing users to create and refine images through conversations with a chatbot rather than having to endlessly perfect the initial prompt (figure 20).
Figure 20. Bing Image Creator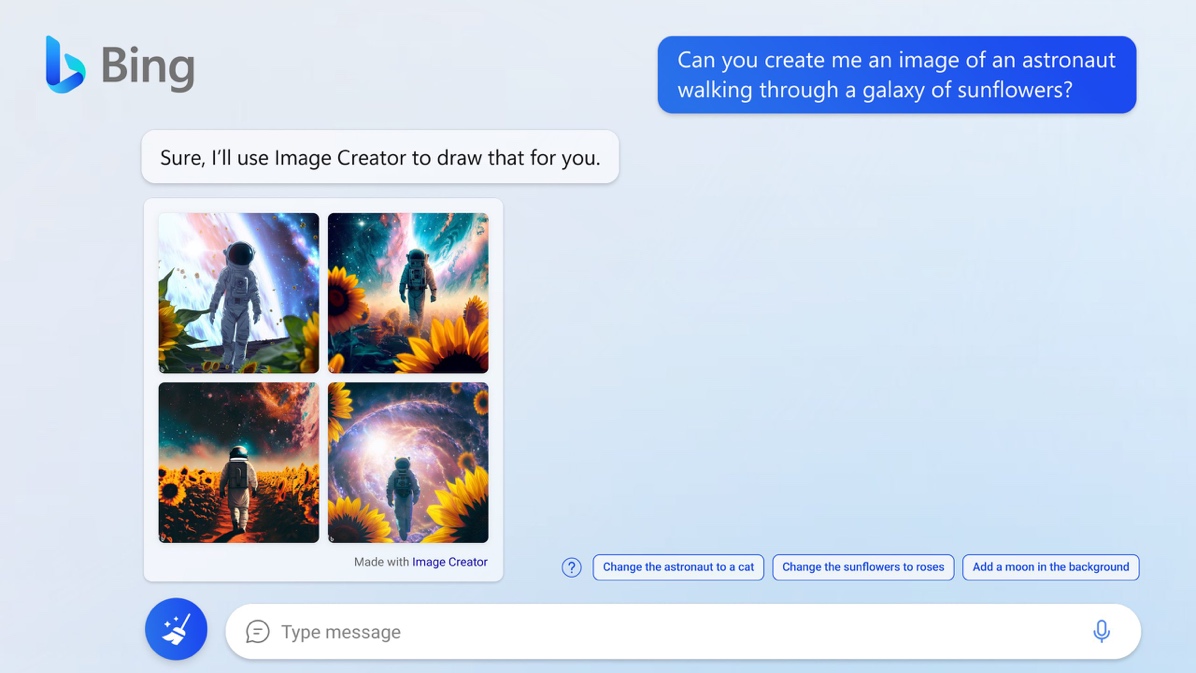
Adobe Firefly
During the Max event in October 2023, Adobe announced three new generative AI models aimed at enhancing its software capabilities. The Firefly Image 2 model, an upgrade to the original Firefly AI image generator, promises higher-quality images with improved high-frequency details such as foliage, skin texture, and facial features (figure 21). It also introduced AI-powered editing capabilities, allowing users to adjust depth of field, motion blur, and field of view. Another feature called "Prompt Guidance" helps users improve text descriptions and automatically completes prompts for increased efficiency.
Adobe also unveiled two additional Firefly models. The Firefly Vector model is touted as the world's first generative AI model for vector graphics, enabling users to create editable vector images using text prompts. The Firefly Design model generates customizable templates for various purposes like print, social media, and video. Adobe's new models are currently available in beta versions, allowing users to test them and provide feedback. The company aims to enhance its product offerings and stay competitive in the AI-powered creative tools market, which has seen similar releases from companies like Canva and Microsoft.
Figure 21. Adobe Firefly
Google Imagen
Google has introduced Imagen, a text-to-image diffusion model that combines large transformer language models with diffusion models to generate high-fidelity images based on text input (figure 22). Imagen surpasses previous methods by leveraging large language models like T5 to achieve superior image-text alignment and sample fidelity.
Imagen creates photorealistic images by encoding text using frozen T5-XXL encoders. These encoders transform the input text into embeddings, which are then mapped to images of increasing resolutions using conditional diffusion models and text-conditional super-resolution diffusion models. Google emphasizes the importance of scaling the size of pre-trained text encoders to achieve better image-text alignment. Imagen has been compared to other models like DALL-E 2 using human raters, who found Imagen to provide superior outputs.
Imagen is accessible through Google's fully managed AI service called Vertex AI. The Model Garden, a collection of Google-developed and open-source models, provides a user interface for Imagen. Similar to other generative art platforms, customers can input prompts to generate candidate images. Imagen also offers editing tools, follow-up prompts, image upscaling, and fine-tuning options to refine the generated images according to customers' preferences. Additionally, Imagen can generate captions for images and translate them using Google Translate.
Figure 22. Google Imagen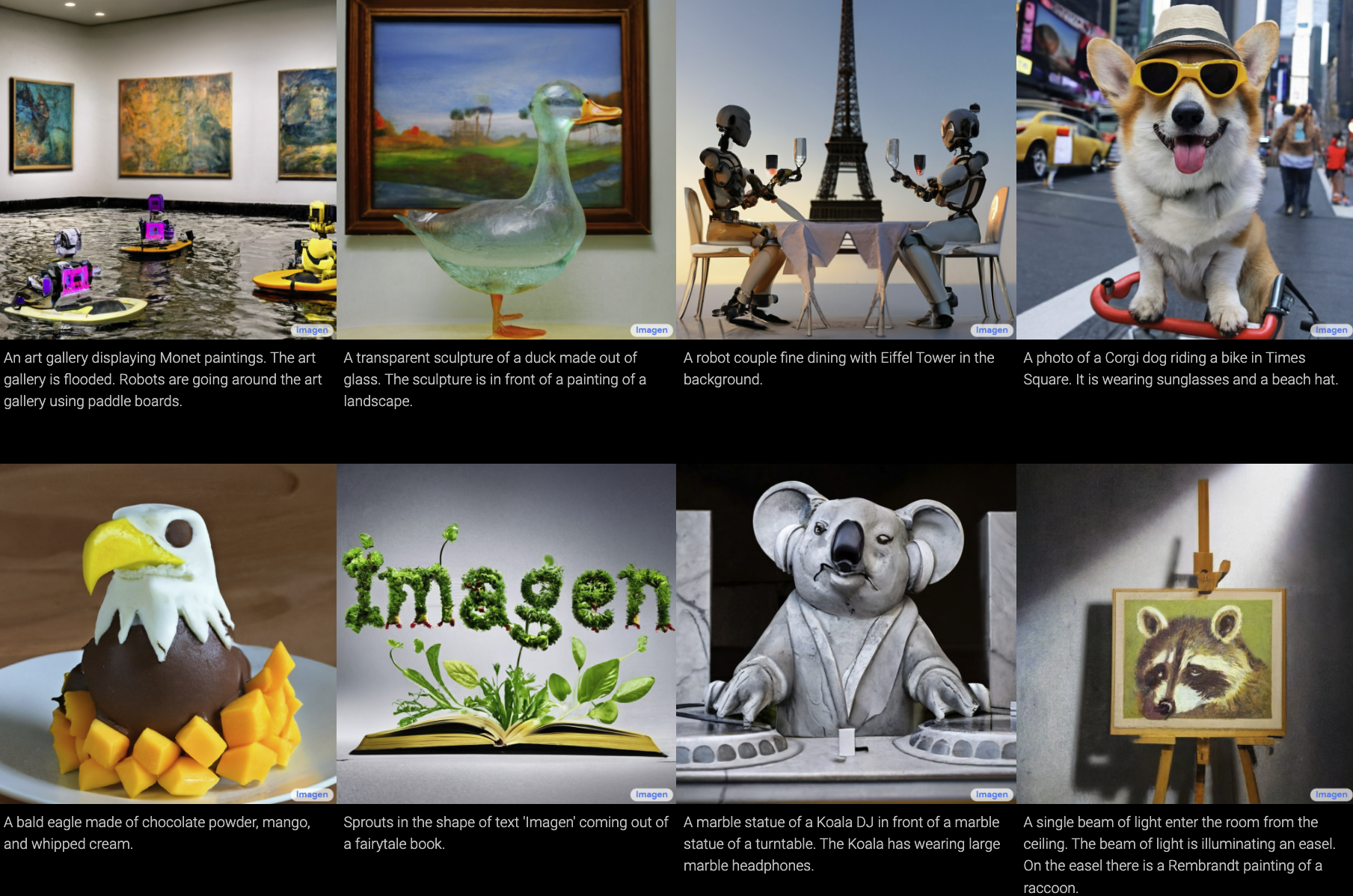
Startup Companies
Runway
Runway, a startup specializing in generative AI tools for multimedia content creators, regarding a $141 million extension to its Series C funding round is significant news in the field of generative AI in June 2023. The funding comes from notable investors such as Google, Nvidia, and Salesforce, among others. This additional capital will be utilized by Runway to expand its in-house research efforts and grow its team. The Series C extension has valued Runway at $1.5 billion, bringing the total amount raised by the company to $237 million. This places Runway among the well-funded generative AI startups, alongside Cohere, Character.ai (which raised $150 million), and Stability AI (which raised approximately $100 million).
Runway, founded in 2018 by Cris Valenzuela, Alejandro Matamala, and Anastasis Germanidis, initially focused on developing AI-powered tools for moviemakers, cinematographers, and photographers. However, over time, the company's focus has shifted towards generative AI, particularly in the realm of video. Their flagship product, Gen-2, is an AI model capable of generating videos based on text prompts or existing images.
Runway has broader aspirations beyond tool development. The startup recently established Runway Studios, an entertainment division that collaborates with enterprise clients as a production partner. Additionally, Runway launched the AI Film Festival, a pioneering event dedicated to showcasing films created either entirely or partially by AI. With a customer base that includes Fortune 500 and Global 2000 companies, as well as millions of individual creators, Runway's success is attributed to the increasing demand for generative AI solutions in content creation. A significant percentage of businesses are either testing or planning to incorporate generative AI tools within the next year, driven by the desire to reduce the costs and time associated with content creation.
StabilityAI
In October 2023, Stability AI, a company focused on developing open-source music and image generation systems such as Dance Diffusion and Stable Diffusion, has recently raised $101 million in a funding round led by Coatue and Lightspeed Venture Partners, with participation from O'Shaughnessy Ventures LLC. This funding round values the company at $1 billion post-money and comes as the demand for AI-powered content generation continues to grow.
Stability AI, based in London and San Francisco, was founded by CEO Emad Mostaque, who holds a master's degree in mathematics and computer science from Oxford. Mostaque, who previously worked as an analyst at hedge funds, started Stability AI in 2020 out of a personal fascination with AI and a perceived lack of organization within the open-source AI community.
Stability AI operates a cluster of over 4,000 Nvidia A100 GPUs in AWS for training AI systems, including Stable Diffusion. While maintaining such a cluster incurs substantial costs, Mostaque believes that ongoing research and development will lead to more efficient model training in the future. In addition to Stable Diffusion, Stability AI is working on other projects with commercial potential, including AI models for generating audio, language, 3D content, and video. Dance Diffusion, an algorithm and toolset that generates music clips by training on a vast amount of existing songs, is one of these projects.
Stability AI plans to generate revenue by training private models for customers and acting as a general infrastructure layer. It also offers DreamStudio, a platform and API that allows individual users to access its models. According to Mostaque, DreamStudio has over 1.5 million users who have created more than 170 million images, and Stable Diffusion has more than 10 million daily users across all channels.
Midjourney
Midjourney is the second-most popular platform in the generative AI space and the leading platform in AI image generation. It has a 40-member team and is projected to generate $200 million in revenue this year from its 15 million community members. The company earns revenue through subscription fees and additional GPU time purchases. Users can subscribe monthly or annually, and they can also purchase extra GPU time at a flat rate. Midjourney has been praised for its efficient and profitable business model and has gained recognition without relying on venture capital funding. Founder David Holz is determined to keep the company self-funded for long-term sustainability. Holz's experience building AI teams at his previous startup, Leap Motion, has influenced his approach to building Midjourney. The company has formed a partnership with Discord, which has helped foster a sense of community among its users. Despite some skepticism, Midjourney plans to maintain a strong presence on Discord. The company operates with a lean structure, relying on external advisers and giving employees a share in profits. It also continues to upgrade its product and has plans to release an improved software version with 3D art and video capabilities.
Outlook and Challenges at a Glance
Outlook
The outlook for AI image generators is bright, as they have a few advantages and bring lots of creativity to many industries. AI image generators have made significant progress in generating realistic images. As algorithms and models continue to advance, we can expect even greater realism, finer details, and improved visual quality in the generated images. These generators support multimodal outputs, such as text-to-image and text-to-video, generating not only images but also other media types such as videos or 3D models. This would enable more diverse and immersive experiences across different mediums. Models like DALL-E, Stable Diffusion, and Midjourney have advanced rapidly in just the past year or so. As more computing power and data are used to train these systems, their ability to generate increasingly complex and realistic images will likely continue improving. AI image generation will become massively available and be integrated into things like graphic/3D design software, video/photo editing tools, games/virtual worlds, and websites/apps as an added creative capability.
Challenges
While AI image generators have made strides in generating realistic images, achieving fine-grained control over specific details can still be challenging. For example, generating realistic and accurate depictions of complex objects or specific human features, such as hands or facial expressions, remains a difficulty. There are concerns about AI image generators being misused to generate deepfakes, fake reviews/testimonials, or propaganda. Ensuring proper usage controls and oversight will be important. Transparency around what was AI-generated vs. human-created is also a challenge. In addition, the ability to generate images from text prompts raises questions about copyright for original creative works. Clear policies around attribution, commercial usage, and derivative works are still evolving.
Investment Insights
In recent years, the improvement of Diffusion Models has laid a strong foundation in AI image generation. The unprecedented ability to realistically generate photographs and artwork from text prompts alone. As image generation models continue advancing in powers like fidelity, originality, and multi-modal abilities, their applications are sure to proliferate across industries. Design, education, media, scientific research, and more could see workflow enhancements through AI creative assistance tools. Prominent startups in this sector such as Runway, Midjourney and StabilityAI have secured significant funding in 2023. It is noticeable that Runway distinguished itself by commercializing text-to-video generation in an efficient and accurate way. We also noticed that the commercial SaaS model is stunning. It is interesting to see that Midjourney attracted millions of subscribers in 2022 and generated an impressive amount of revenue without external funding.
On the consumer side, accessible mobile and web apps may soon allow billions of people to integrate AI image generation into daily life for fun, school, work, or remote collaboration. Entirely new forms of visual entertainment, art and self-expression are already available. While technical challenges remain around general intelligence, specialization in artistic enfranchisement is growing rapidly. In addition to the potential use cases, AI image generation may pose oversight challenges regarding appropriate usage, content regulation, intellectual property, bias and more. Ensuring AI image generators are developed and applied responsibly will be paramount as the technology infiltrates every facet of business and society.
Overall, while AI image generation is still booming in the emerging technology market, the innovation underway and foreseeable applications suggest transformative impacts and investment opportunities across industries. This nascent industry commands immense long-term potential. Companies leading the way in foundational AI model research and large language model scaling are attracting massive funding rounds. Startups tackling specialized commercial and enterprise applications also have promise, though risks are pronounced. With prudence and guidance, this emerging field has all the hallmarks of becoming a true general purpose technology upon which new wealth and prosperity may be built. Careful selection and due diligence will help investors profit from the Dawn of the AI Renaissance.